In this blog post, I will look into the implementation details of CPython’s Global Interpreter Lock (GIL)
and how they changed between Python 3.9 and the current development branch that will become Python 3.13.
My goal is to understand which concrete “guarantees” the GIL gives in both versions,
which “guarantees” it does not give,
and which ones one might assume based on testing and observation.
I am putting “guarantees” in quotes, because with a future no-GIL Python,
none of the discussed properties should be considered language guarantees.
While Python has various implementations,
including CPython, PyPy, Jython, IronPython, and GraalPy,
I’ll focus on CPython as the most widely used implementation.
Though, PyPy and GraalPy also use a GIL,
but their implementations subtly differ from CPython’s,
as we will see a little later.
1. What Is the GIL?
Let’s recap a bit of background.
When CPython started to support multiple operating system threads,
it became necessary to protect various CPython-internal data structures from concurrent access.
Instead of adding locks or using atomic operations to protect the correctness of for instance reference counting,
the content of lists, dictionaries, or internal data structures,
the CPython developers decided to take a simpler approach
and use a single global lock, the GIL, to protect all of these data structures from incorrect concurrent accesses.
As a result, one can start multiple threads in CPython,
though only a single of them runs Python bytecode at any given time.
The main benefit of this approach is its simplicity and single-threaded performance.
Because there’s only a single lock to worry about,
it’s easy to get the implementation correct without risking deadlocks or other subtle concurrency bugs
at the level of the CPython interpreter.
Thus, the GIL represented a suitable point in the engineering trade-off space between correctness and performance.
Of course, the obvious downside of this design is
that only a single thread can execute Python bytecode at any given time.
I am talking about Python bytecode here again,
because operations that may take a long time, for instance reading a file into memory,
can release the GIL and allow other threads to run in parallel.
For programs that spend most of their time executing Python code,
the GIL is of course a huge performance bottleneck,
and thus, PEP 703 proposes to make the GIL optional.
The PEP mentions various use cases, including machine learning, data science, and other numerical applications.
3. Which “Guarantees” Does the GIL Provide?
So far, I only mentioned that the GIL is there to protect CPython’s internal data structures
from concurrent accesses to ensure correctness.
However, when writing Python code, I am more interested in the “correctness guarantees” the GIL gives me
for the concurrent code that I write.
To know these “correctness guarantees”, we need to delve into the implementation details of when the GIL is acquired and released.
The general approach is that a Python thread obtains the GIL when it starts executing Python bytecode.
It will hold the GIL as long as it needs to and eventually release it, for instance when it is done executing,
or when it is executing some operation that often would be long-running and itself does not require the GIL for correctness.
This includes for instance the aforementioned file reading operation or more generally any I/O operation.
However, a thread may also release the GIL when executing specific bytecodes.
This is where Python 3.9 and 3.13 differ substantially.
Let’s start with Python 3.13, which I think roughly corresponds to what Python has been doing since version 3.10 (roughly since this PR).
Here, the most relevant bytecodes are for function or method calls
as well as bytecodes that jump back to the top of a loop or function.
Thus, only a few bytecodes check whether there was a request to release the GIL.
In contrast, in Python 3.9 and earlier versions,
the GIL is released at least in some situations by almost all bytecodes.
Only a small set of bytecodes including stack operations,
LOAD_FAST, LOAD_CONST, STORE_FAST, UNARY_POSITIVE, IS_OP, CONTAINS_OP, and JUMP_FORWARD do not
check whether the GIL should be released.
These bytecodes all use the CHECK_EVAL_BREAKER() on 3.13
(src)
or DISPATCH() on 3.9 (src),
which eventually checks (3.13, 3.9)
whether another thread requested the GIL to be released by setting the GIL_DROP_REQUEST bit in the interpreter’s state.
What makes “atomicity guarantees” more complicated to reason about is that this bit is set by threads waiting for the GIL
based on a timeout (src).
The timeout is specified by sys.setswitchinterval().
In practice, what does this mean?
For Python 3.13, this should mean that a function that contains only bytecodes
that do not lead to a CHECK_EVAL_BREAKER() check should be atomic.
For Python 3.9, this means a very small set of bytecode sequences can be atomic,
though, except for a tiny set of specific cases, one can assume that a bytecode sequence is not atomic.
However, since the Python community is taking steps that may lead to the removal of the GIL,
the changes in recent Python versions to give much stronger atomicity “guarantees”
are likely a step in the wrong direction for the correctness of concurrent Python code.
I mean this in the sense of people to accidentally rely on these implementation details,
leading to hard to find concurrency bugs when running on a no-GIL Python.
4. Which Guarantees Might One Incorrectly Assume the GIL Provides?
Thanks to @cfbolz,
I have at least one very concrete example of code that someone assumed to be atomic:
request_id = self._next_id
self._next_id += 1
The code tries to solve a classic problem: we want to hand out unique request ids,
but it breaks when multiple threads execute this code at the same time,
or rather interleaved with each other.
Because then we end up getting the same id multiple times.
This concrete bug was fixed by making the reading and incrementing atomic using a lock.
On Python 3.9, we can relatively easily demonstrate the issue:
def get_id(self):
# expected to be atomic: start
request_id = self.id
self.id += 1
# expected to be atomic: end
self.usage[request_id % 1_000] += 1
Running this on multiple threads will allow us to observe an inconsistent number of usage counts.
They should be all the same, but they are not.
Arguably, it’s not clear whether the observed atomicity issue is from the request_id or the usage counts,
but the underlying issue is the same in both cases.
For the full example see 999_example_bug.py.
This repository contains a number of other examples that demonstrate the difference between
different Python implementations and versions.
Generally, on Python 3.13 most bytecode sequences without function calls will be atomic.
On Python 3.9, much few are,
and I believe that would be better to avoid people from creating code that relies on the very
strong guarantees that Python 3.13 gives.
As mentioned earlier,
because the GIL is released based on a timeout,
one may also perceive bytecode sequences as atomic when experimenting.
Let’s assume we run the following two functions on threads in parallel:
def insert_fn(list):
for i in range(100_000_000):
list.append(1)
list.append(1)
list.pop()
list.pop()
return True
def size_fn(list):
for i in range(100_000_000):
l = len(list)
assert l % 2 == 0, f"List length was {l} at attempt {i}"
return True
Depending on how fast the machine is, it may take 10,000 or more iterations of the loop
in size_fn before we see the length of the list to be odd.
This means it takes 10,000 iterations before the function calls to append or pop allowed
the GIL to be released before the second append(1) or after the first pop().
Without looking at the CPython source code, one might have concluded easily
that these bytecode sequences are atomic.
Though, there’s a way to make it visible earlier.
By setting the thread switch interval to a very small value,
for instance with sys.setswitchinterval(0.000000000001),
one can observe an odd list length after only a few or few hundred iterations of the loop.
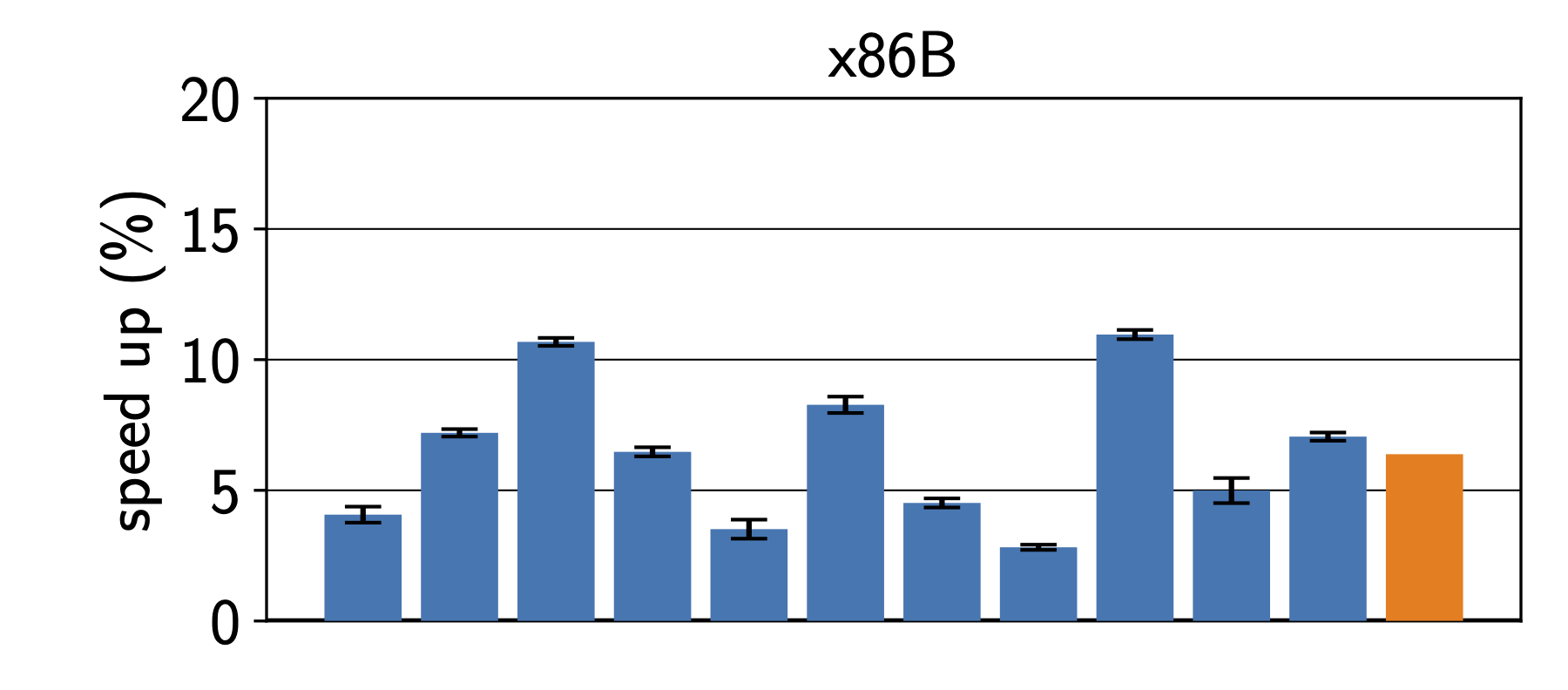
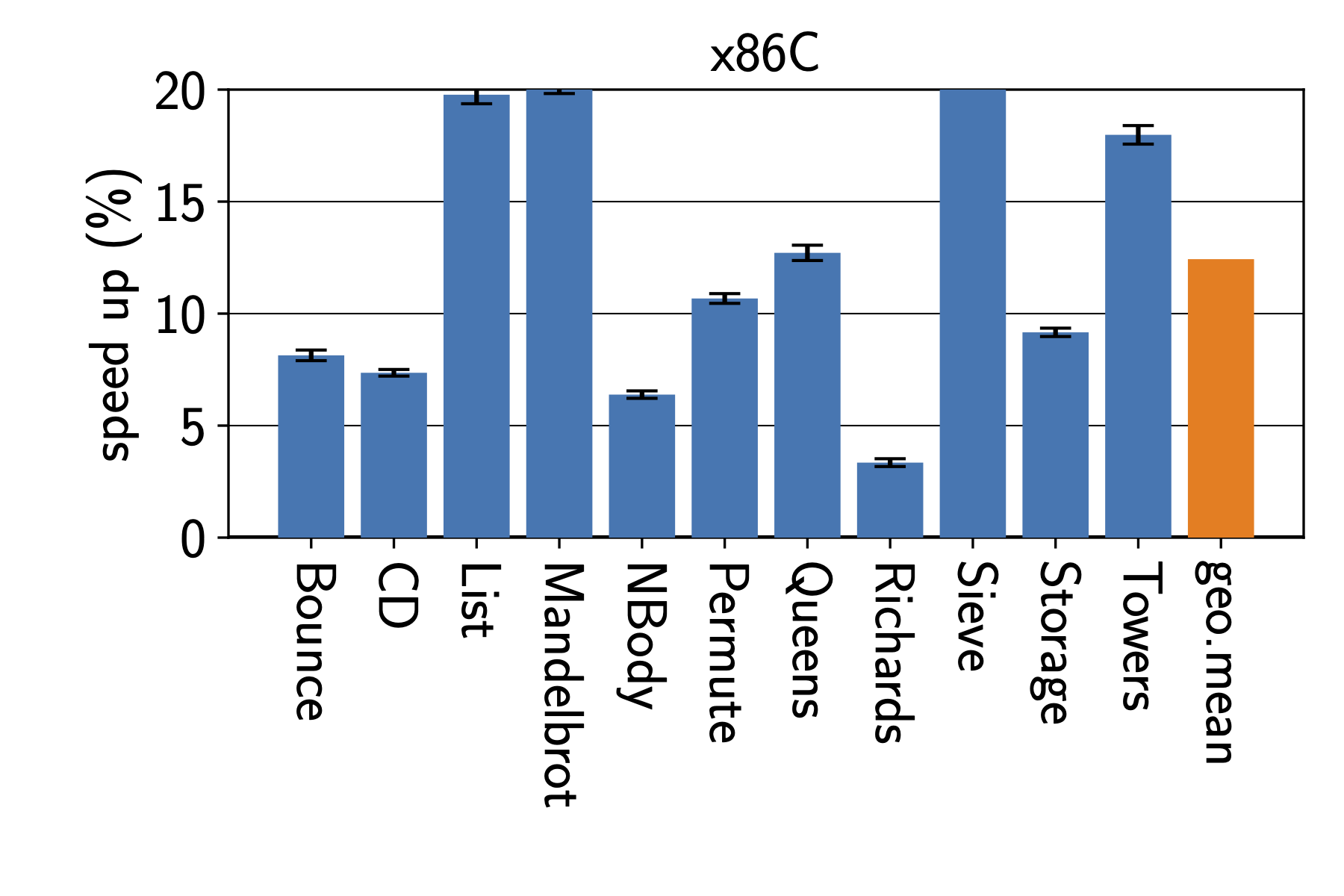
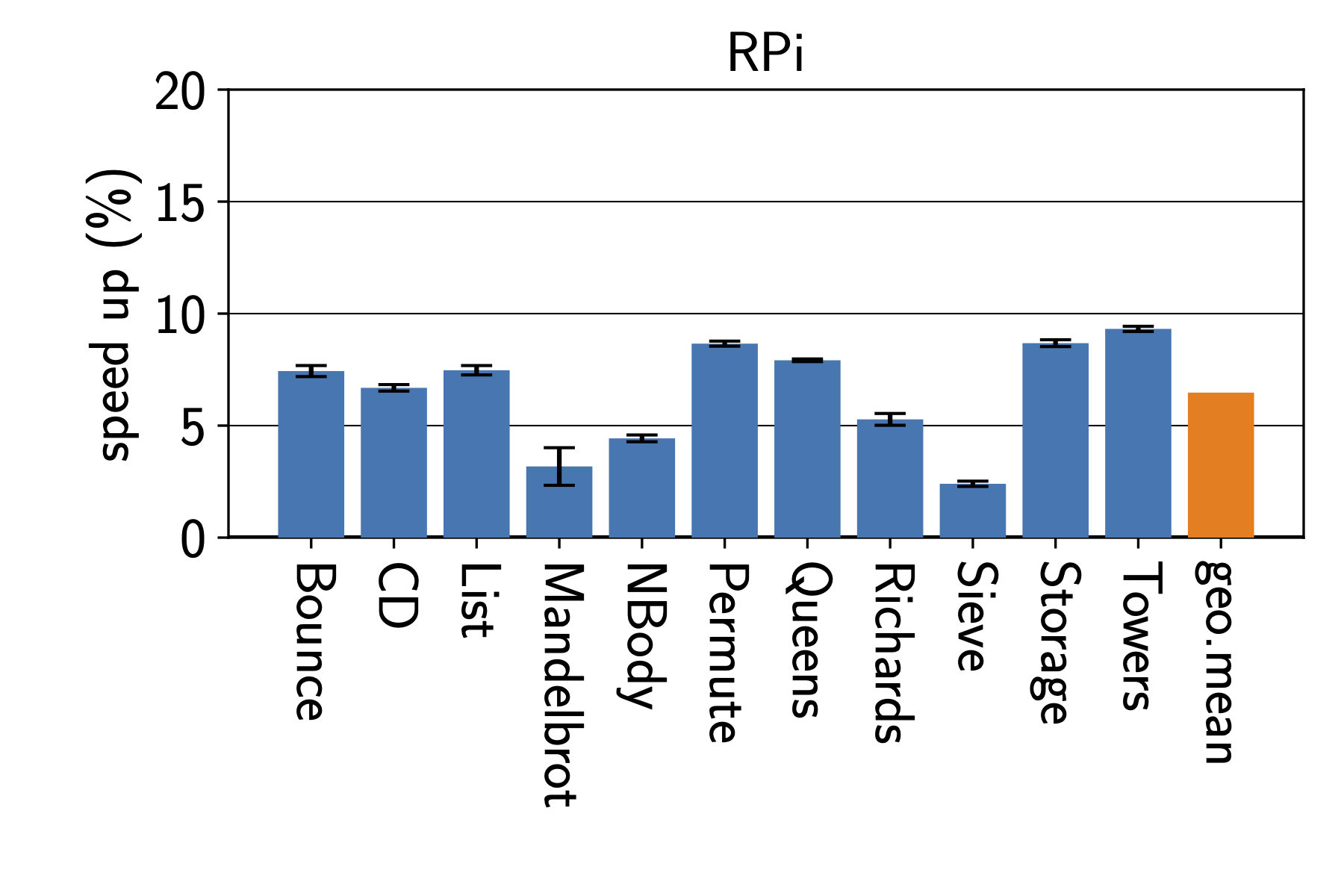
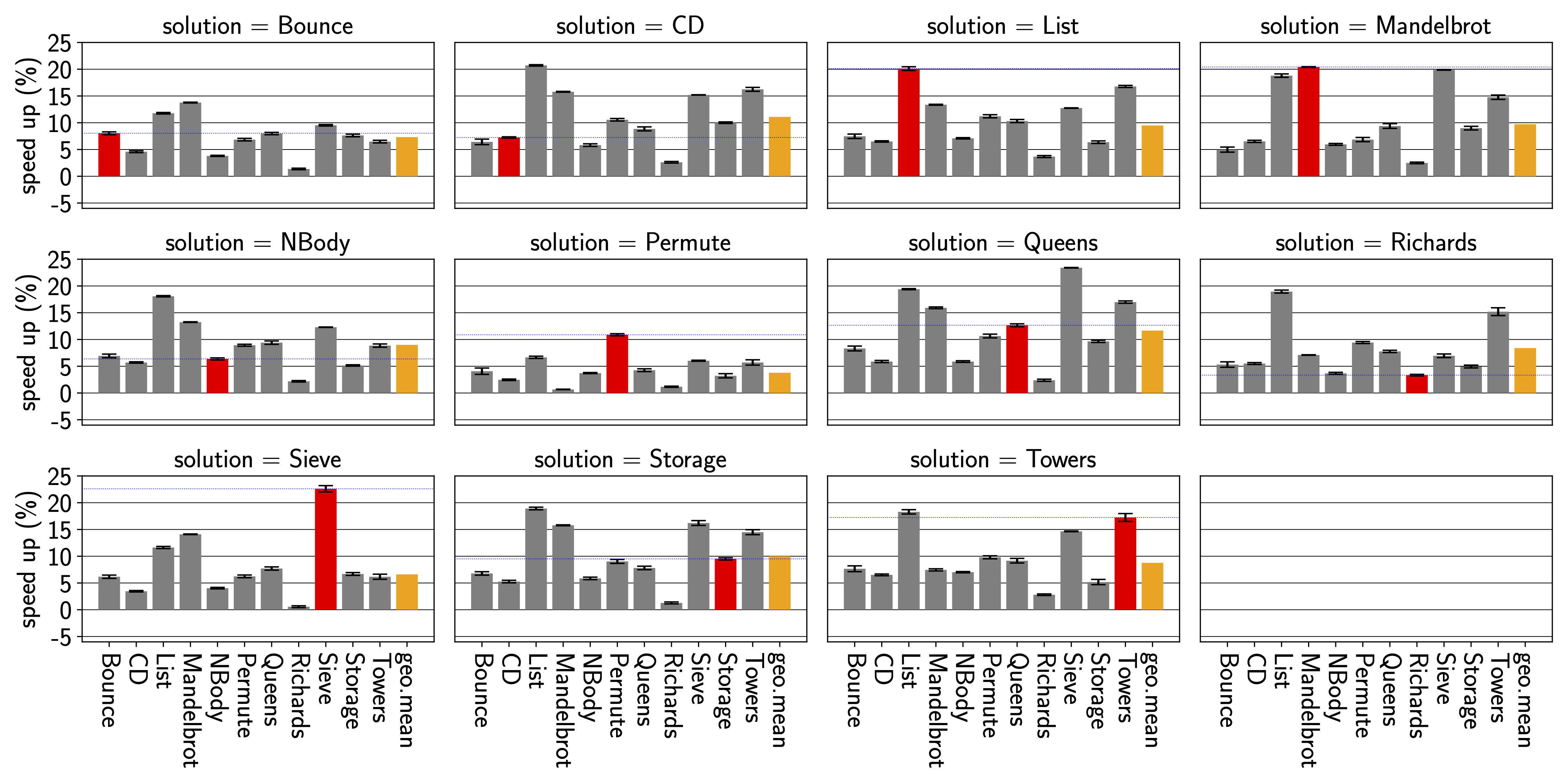
5. Comparing Observable GIL Behavior for Different CPython Versions, PyPy, and GraalPy
In my gil-sem-demos repository,
I have a number of examples that try to demonstrate observable differences in GIL behavior.
Of course, the very first example tries to show the performance benefit
of running multiple Python threads in parallel.
Using the no-GIL implementation,
one indeed sees the expected parallel speedup.
On the other tests,
we see the major differences between Python 3.8 - 3.9
and the later 3.10 - 3.13 versions.
The latter versions usually execute the examples without seeing
results that show a bytecode-level atomicity granularity.
Instead, they suggest that loop bodies without function calls
are pretty much atomic.
For PyPy and GraalPy, it is also harder to observe the bytecode-level atomicity granularity,
because they are simply faster.
Lowering the switch interval makes it a little more observable,
except for GraalPy, which likely aggressively removes the checks for whether to release the GIL.
Another detail for the no-GIL implementation: it crashes for our earlier bug example.
It complains about *** stack smashing detected ***.
A full log is available as a gist.
6. Conclusion
In this blog post, I looked into the implementation details of CPython’s Global Interpreter Lock (GIL).
The semantics between Python 3.9 and 3.13 differ substantially.
Python 3.13 gives much stronger atomicity “guarantees”,
releasing the GIL basically only on function calls and jumps back to the top of a loop or function.
If the Python community intends to remove the GIL,
this seems problematic.
I would expect more people to implicitly rely on these much stronger guarantees,
whether consciously or not.
My guess would be that this change was done mostly in an effort to improve the
single-threaded performance of CPython.
To enable people to test their code on these versions closer to semantics
that match a no-GIL implementation,
I would suggest to add a compile-time option to CPython that forces
a GIL release and thread switch after bytecodes that may trigger behavior
visible to other threads.
This way, people would have a chance to test on a stable system that is closer
to the future no-GIL semantics and probably only minimally slower at executing unit tests.
Any comments, suggestions, or questions are also greatly appreciated
perhaps on Twitter @smarr or Mastodon.
]]>