 I head the
I head the
The Shape of 6M Lines of Ruby
Following up on my last blog post, I am going to look at how Ruby is used to get a bit of an impression of whether there are major differences between Ruby and Smalltalk in their usage.
Again, I am going to look into the structural aspects of code bases. This means, looking at classes, methods, modules, and files.
Methodology
Not being a Ruby expert, I searched for large Ruby on Rails applications that could be of relevance. I found 10 that sounded promising: Diaspora, Discourse, Errbit, Fat Free CRM, GitLab, Kandan, Redmine, Refinery CMS, Selfstarted, Spree.
For each, I checked out the git repository (see version detail in appendix), and installed the Gems in a local directory. Since there’s a lot of overlap, I moved all gems into a single directory, and only kept the latest version to avoid counting the same, or sufficiently similar code multiple times.
With these projects and their dependencies, I had in the end
10 projects and 861 gems.
Looking exclusively at the *.rb files,
the analysis considered 50,865 files,
with a total of 6,081,070 lines.
To analyze the code, I am building on top of the parser gem. The code to determine the statistics can be found in the ruby-stats project on GitHub.
Size of the Overall Code Base
Looking at the 50,865 files with their overall 6,081,070 lines, the first thing I noticed is that only about 64% of the lines are code, i.e., they are not empty and are not just comments. However, only 46% of all lines are attributed to some form of method or closure, which seemed unexpected to me.
2% of the code lines are simply in the direct body of a file, 6% are directly in modules, and 11% are directly in classes. And there are 19 gems that don’t define a single method or closure. The examples I looked at looked like either meta gems, including others (rspec), gems with JavaScript (babel-source), or data (mime-types-data).
In total, there are 625,761 methods (incl. closures), 32,897 classes, and 11,057 modules defined in all projects.
Of the 50,865 files, 12,150 were classified as tests, for which I more or less checked whether the file name or path contains a variant of “test” or “spec”.
To get an impression how files and classes are used by projects, let’s look at the number of files per project as a histogram:
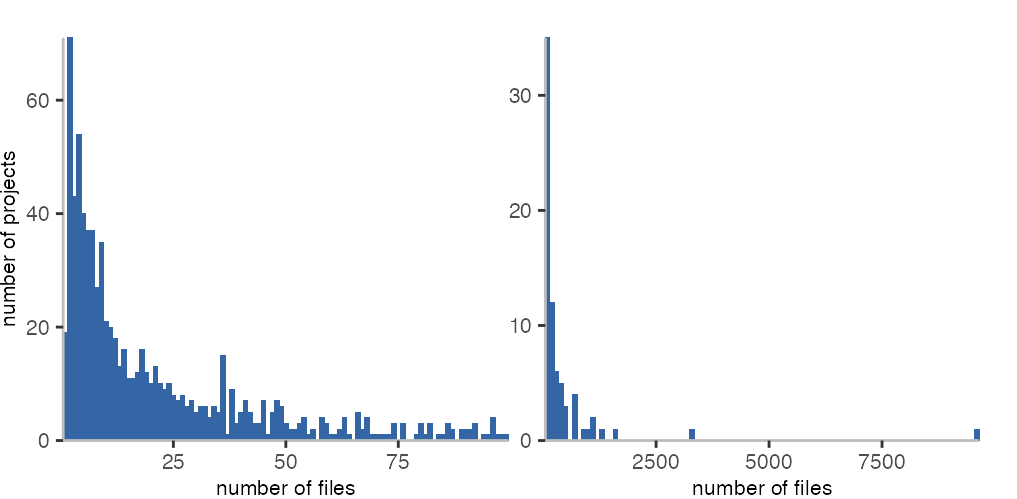
The histograms show how many projects have a specific number of files in them.
There’s less than 20 projects with just a single *.rb file.
The largest project is GitLab with more than 9,500 files.
The next project is Discourse, with about 3,300 files.
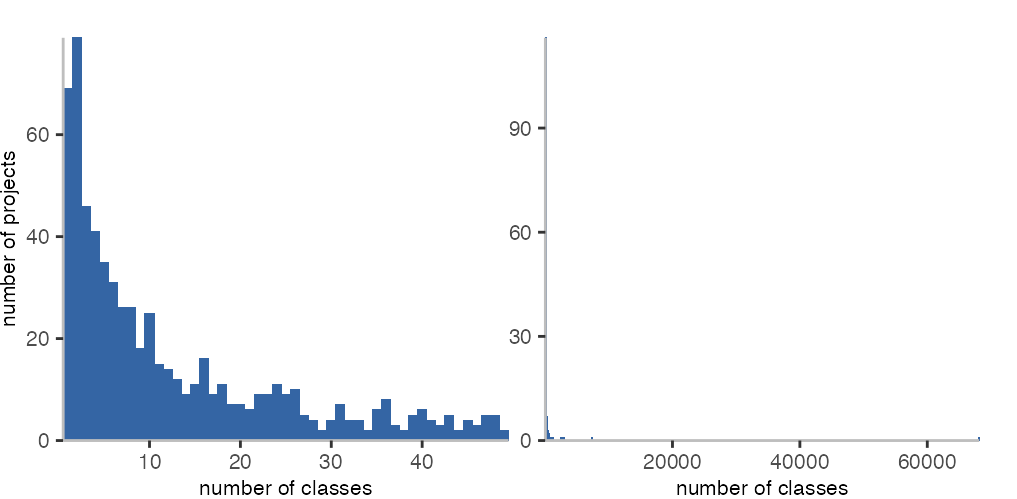
When looking at classes, 823 out of 871 projects have at least one. In the histogram above, we can see that most of the projects that have classes, have indeed rather few of them. Discourse with about 2,000 classes and GitLab with about 3,000 classes again have the most.
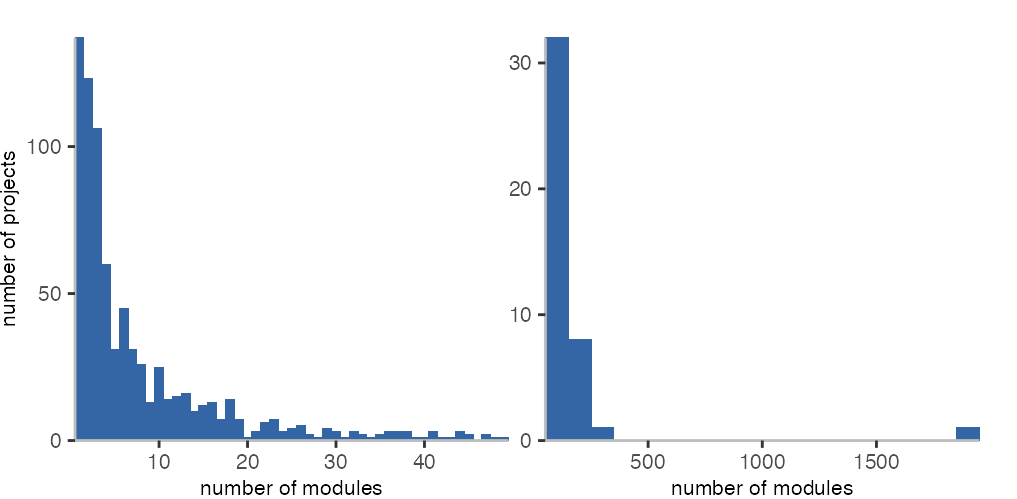
The use of modules seems to be somewhat similar as we can see in the histograms above.
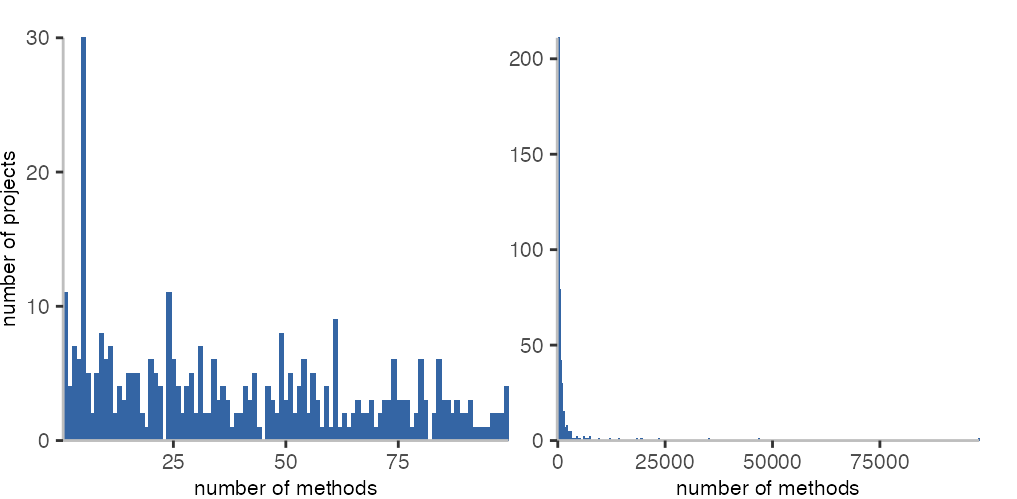
When looking at methods per project, we see that the results look a bit different. There also seem to be some strange patterns and spikes, especially in the range from 1 to 100 methods per project.
Structure of Classes
When looking at the defined classes, we can see in the following histograms that there are many classes that have no or very few methods.
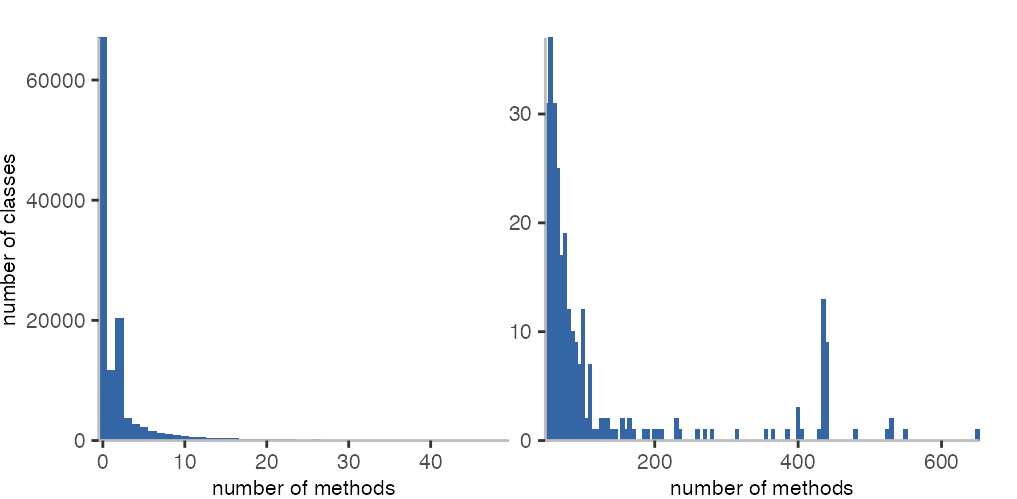
However, there’s also a bunch of classes with more than 200 methods. Most of these classes are for Ruby parsers of the different versions of Ruby. Others are unit test classes in the Redmine project.
While Ruby and Smalltalk are two very different programming systems, the languages have some similarities. So, let’s see whether classes have a similar number of methods:
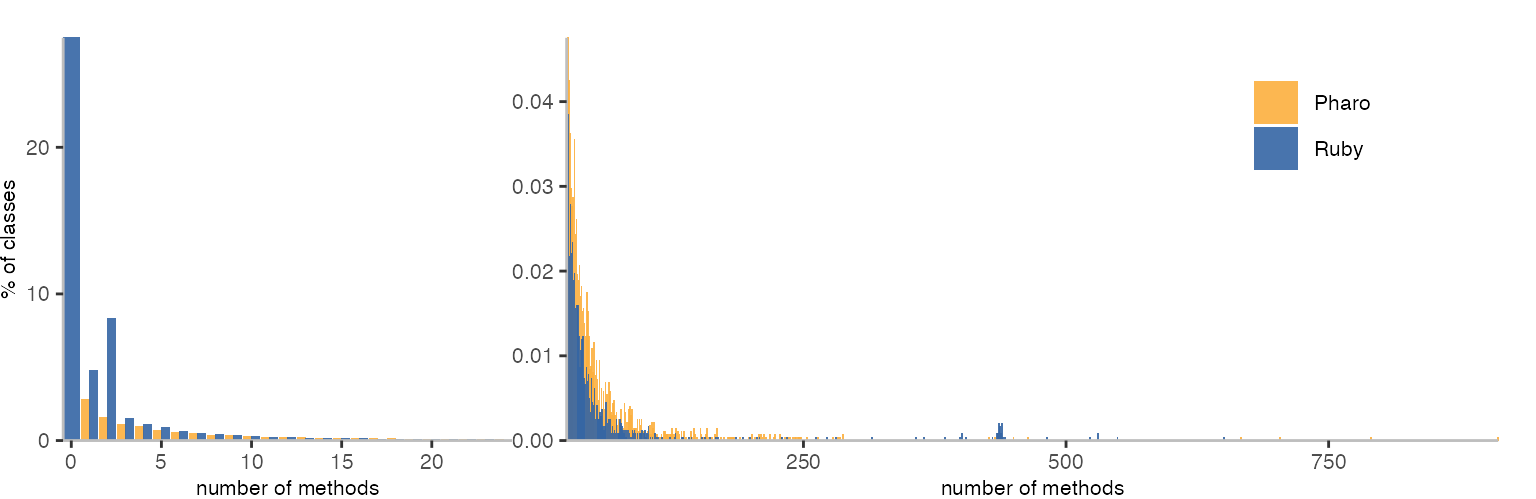
The above plot is similar to our histograms before. But instead of showing the number of classes, it shows the percent of classes with a specific number of methods. By normalizing the values, we can more easily compare between the two corpora. Just to make the semantics of the plot clear: the length of all bars together add up to 100% for Ruby and Pharo separately.
One artifact of how the data is collected, is that Pharo does not show any classes without methods, because I collected it per method, and didn’t get details for classes separately.
The major difference we can see is that Ruby has many more classes with only one or two methods. On the other hand, it seems to have a little fewer larger classes, but then ends up having also a few really large classes. As mentioned previously, the really large classes grouping around 430-ish methods are all variants of Ruby parsers. I’d assume there to be a large amount of code duplication between those classes.
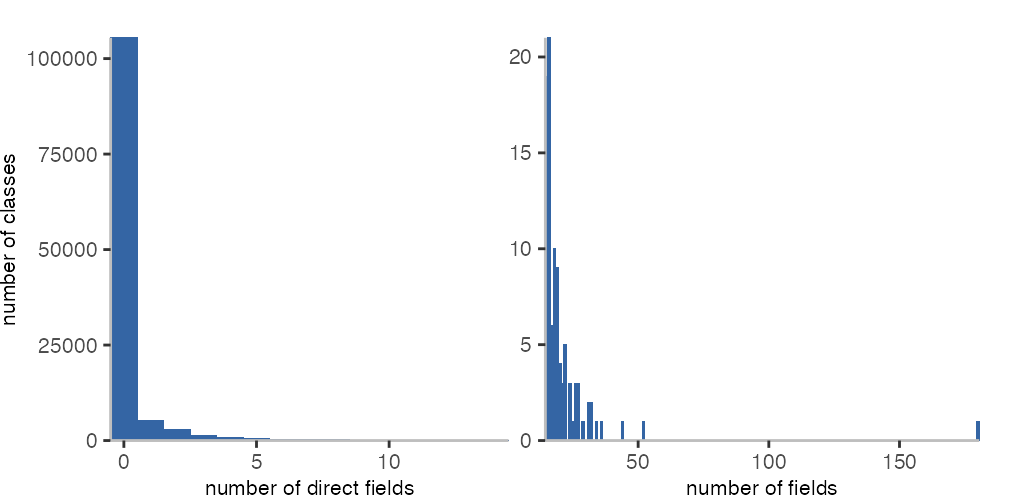
The histograms above show how many classes have a specific number of fields
that they access directly, for instance, with expressions like @count.
We can see that an overwhelming number of classes do not access fields at all, which seems a bit surprising to me. Though, there also seem to be a number of classes that have many fields. The two largest classes have 180 (RBPDF) and 52 distinct fields (csv.Parser).
I’ll refrain from a direct comparison with Pharo here, because it’s not really clear to me how to do this in a comparable way. The only way that would seem somewhat comparable would be to build the inheritance hierarchy, and resolve mixins, but so far, I haven’t implemented either.
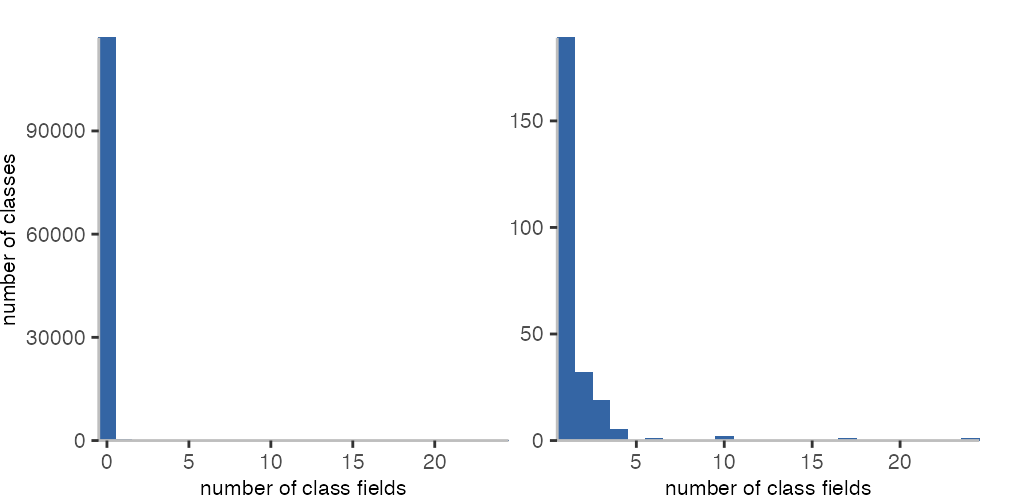
However, we can look at the use of class variables with the double-at syntax: @@count.
Here, the situation looks very different.
Only 189 classes have one class field,
and only 61 have more than one.
This means, 117,079 classes
don’t use class fields at all.
Structure of Methods
After looking at classes, let’s investigate the methods a bit closer.
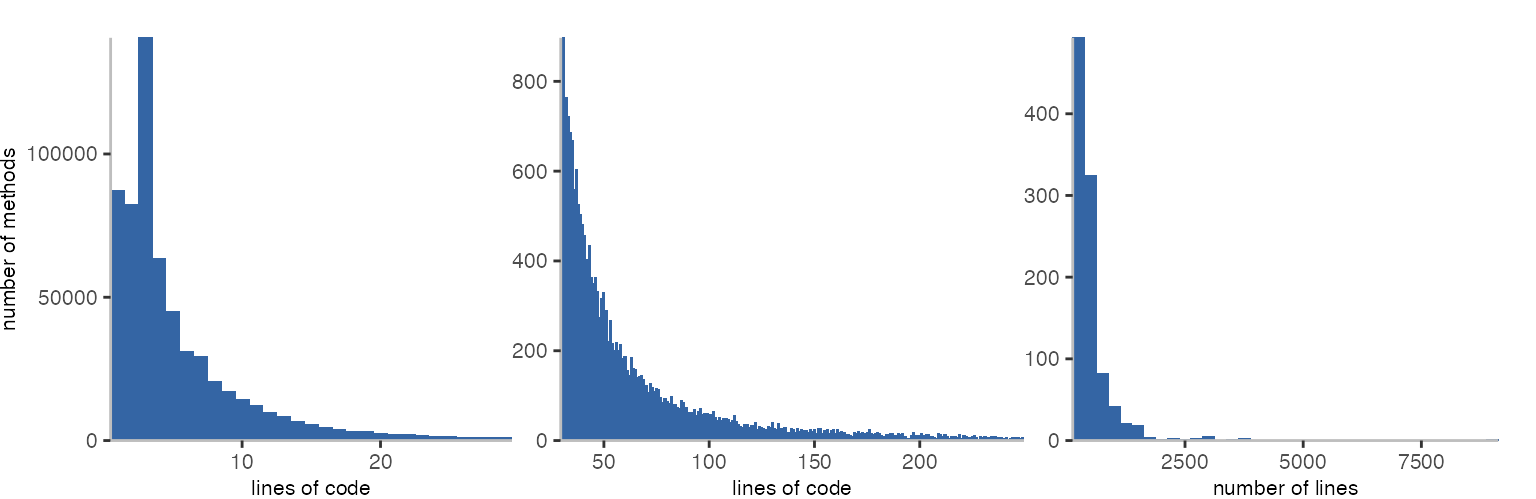
Let’s first look at the lines of code per method. This means, at how many non-empty lines there are that do not only contain comments.
There don’t seem to be any empty methods, but there are almost an equal number of methods with 1 (87,217) or 2 lines of code (82,467).
The largest method in the corpus is parser.Lexer.advance. I suppose, unsurprisingly
that’s the Ruby parser again with 8,888 lines of code.
It also has 55 local variables.
The other methods with over 3,000 lines of code are actually blocks in specs. There’s 5 of them in the mongoid gem, one in grape, and one in Discourse.
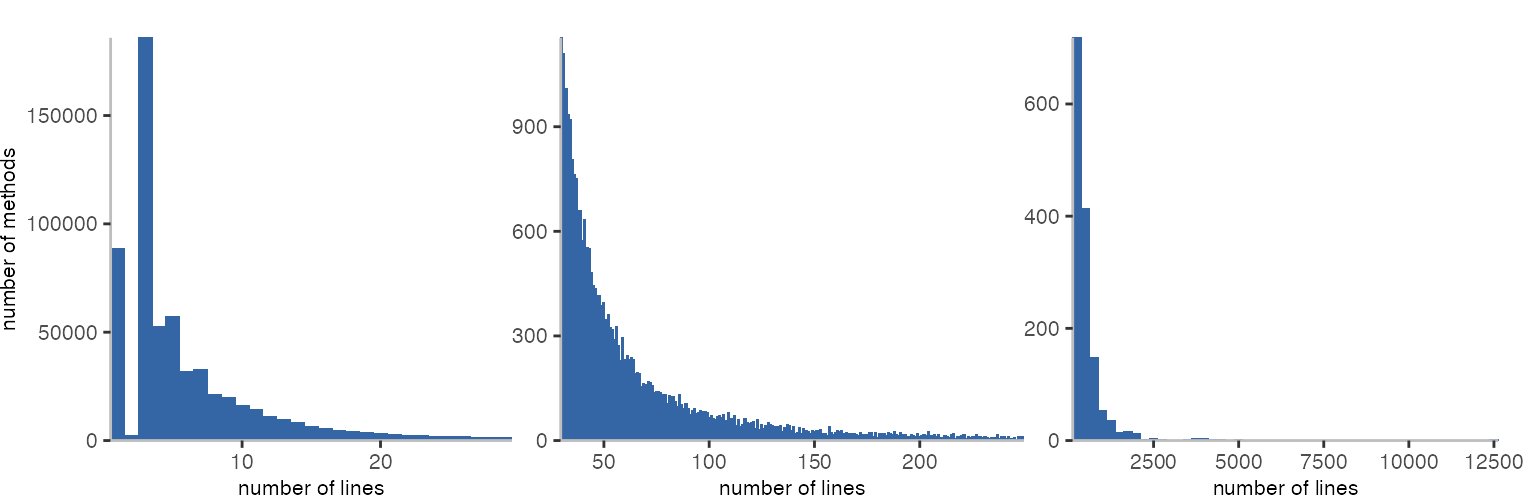
When looking at the data for method length in lines, which also counts blank lines and comments, the results seem a bit wonky. From the previous results, I would expect that there are no empty methods, which indeed is the case.
Then we got 88,803 methods with just one line, which seems in line with expectations. However, we got 2,267 methods with two lines, and 185,876 methods with three lines, which seems a little odd. Perhaps there is some code formatting convention at play.
The rest looks reasonably similar to the lines of code results. The huge methods are again the parser this time with 12,619 lines, and the spec blocks.
Comparing to Pharo is a little bit of an issue, because neither the line count nor the lines of code metric match what Pharo gives me. Pharo reports the number of non-empty lines, including comments. So, Pharo’s metric is somewhere between the lines and lines of code I got here for Ruby.
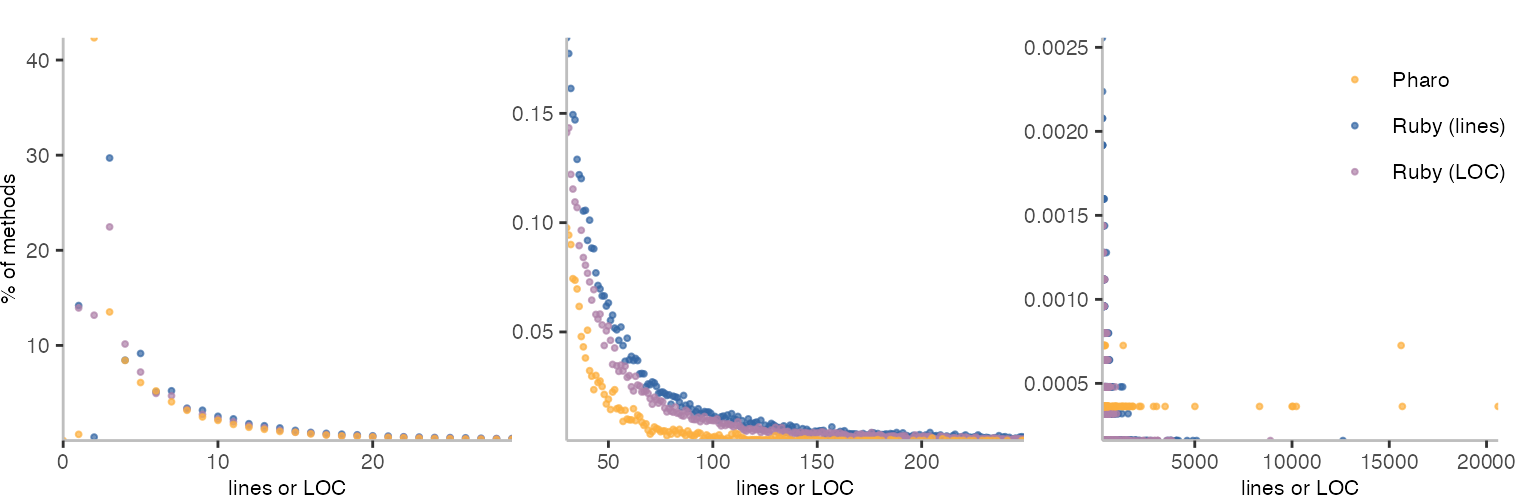
While the metrics are not identical, having both the lines and lines of code for Ruby lets us draw at least one conclusion from the comparison. There seems to be a tendency for longer methods in Ruby. At least in the range from 30 to 250 lines, there seem to be more methods with this size in Ruby.
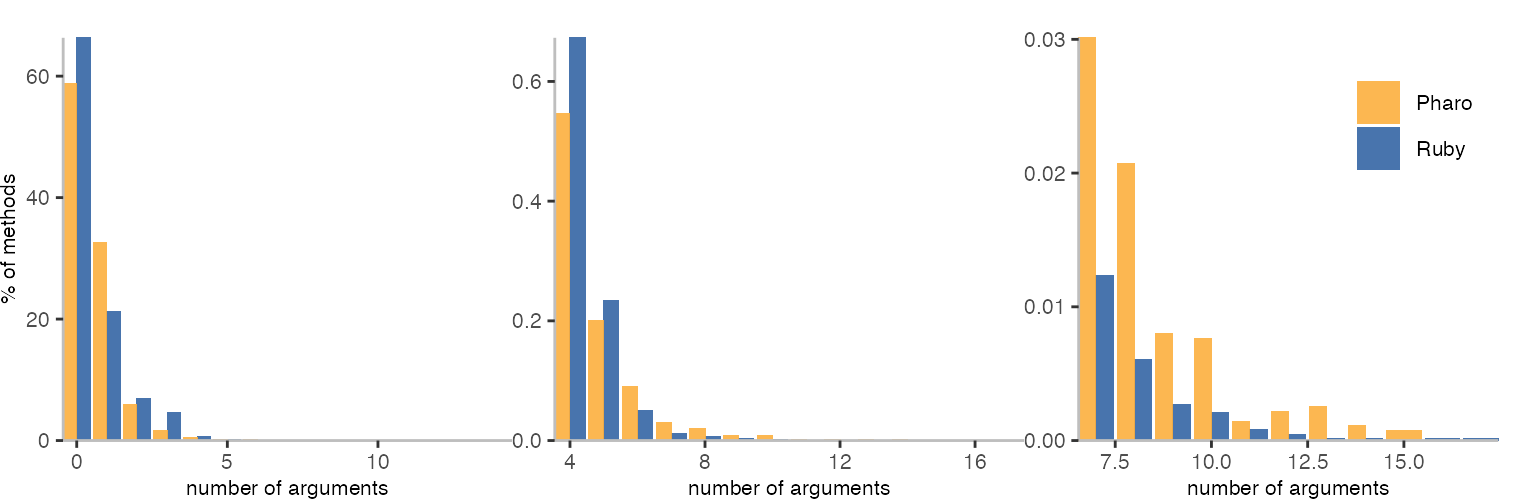
When it comes to arguments, Ruby seems to have a few methods/blocks/lambdas without any argument. But a bit few with one argument. When it comes to methods/blocks/lambdas with many arguments, Pharo seems to have a few more of those. Though, the numbers here are not entirely comparable, because the Pharo numbers do not actually include blocks/closures.
The Ruby methods with the largest number of arguments (16 and 17) are RBPDF.Text and RBPDF.Image.
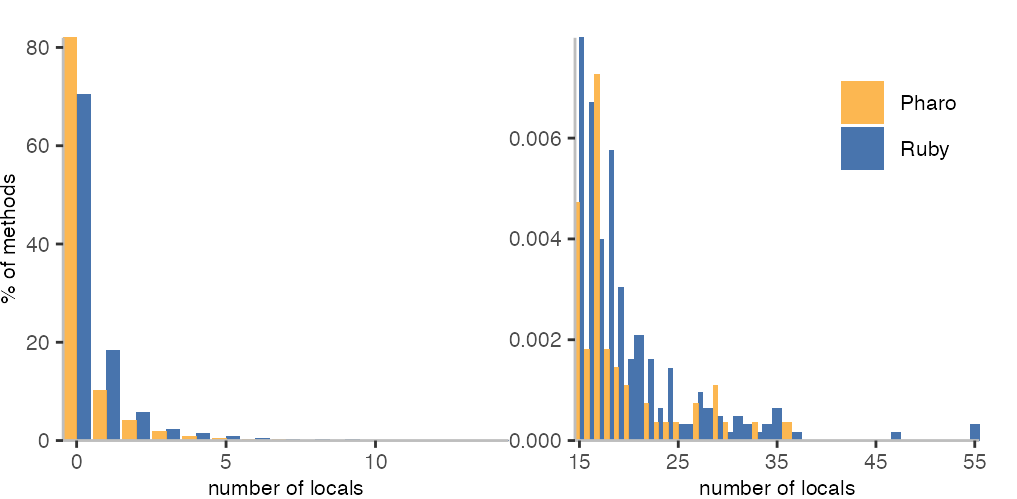
In both languages, a lot of methods don’t have any local variables.
However, in the Ruby corpus there are three methods with more than 50 local variables.
That is the very long Lexer.advance method in the Ruby parser, a Markdown code processing method,
and RBPDF’s writeHTML method.
Conclusion
For me, the main take away from this exercise is that when it comes to structural metrics, there are visible differences between Ruby and Pharo code. This isn’t surprising, since they are different languages, with different features, communities, and style guides.
However, there also seem to be similarities that are worth noting. Overall, number of methods in a class seems to be fairly similar. And while Ruby methods might have a small tendency of being larger when they are large, the majority of methods isn’t actually large and here both languages seem to show fairly similar method sizes.
The difference in the usage of arguments may or may not be explainable with syntax, such as implicit block arguments, or that I didn’t actually consider closures in Pharo. The use of local variables however, seems to be fairly similar between both languages.
Not sure there are any big lessons to be learned yet, but one could probably go further and study other metrics to gain additional insights. I’d probably start with class hierarchy, mixins, and other features that require either a bit of dynamic evaluation, or implementing the Ruby semantics in the tool determining the metrics.
For suggestions, comments, or questions, find me on Twitter @smarr.
Appendix
The following table contains the details on the projects included in this analysis.
| Project | Commit | URL |
|---|---|---|
| Diaspora | d2acad1 | https://github.com/diaspora/diaspora |
| Discourse | f040b5d | https://github.com/discourse/discourse |
| Errbit | cf792c0 | https://github.com/errbit/errbit |
| Fat Free CRM | 4e72e0c | https://github.com/fatfreecrm/fat_free_crm |
| GitLab | 21e08b6 | https://github.com/gitlabhq/gitlabhq |
| Kandan | 380efaf | https://github.com/kandanapp/kandan |
| Redmine | 988a36b | https://github.com/edavis10/redmine |
| Refinery CMS | 1b73e0b | https://github.com/refinery/refinerycms |
| Selfstarted | 740075f | https://github.com/apigy/selfstarter |
| Spree | 901cb64 | https://github.com/spree/spree |