 I head the
I head the
The Shape of 1.7M Lines of Code
Recently, I was wondering how large code bases look like when it comes to the basic properties compiler might care about. And here I am not thinking about dynamic properties, but simply static properties such as length of methods, number of methods per class, number of fields, and so on.
I think there are a whole bunch of studies that ask questions related to this. And a quick search let me to a report titled Characterizing Pharo Code by Zaitsev et al., which also comes with the code the authors used to answer their questions.
Though, the report focuses on more high-level questions than what I had in mind. With a bit of extra effort, I managed to collect the data I was looking for.
Methodology
The report by Zaitsev et al. selected Pharo projects that represent a variety of different domains, widely used and less widely used projects, small and large ones, as well as active and less active projects. I kept the same selection of projects, but with a slightly more recent set of commits to look at.
Furthermore, I included the whole Pharo 8.0 base system and all loaded dependencies, which didn’t seem to be the case in the original analysis.
A full list of projects and commits is included at the end of this post. Overall, the analysis considers 183 projects, with 1,403 packages in total. A “project” is here a set of Pharo packages that are related by name. This includes for instance Moose, a platform for software and data analysis, Seaside, a web application framework, Roassal, scripting for visualizations, and various other packages, including the Pharo system itself.
Since Pharo has the classic introspection/reflection facilities of Smalltalk systems, I use them to collect the structural metrics, including lines of code, number of methods, classes, arguments, and local variables.
Size of the Overall Code Base
As mentioned earlier, the code base under investigation is composed of 183 projects. These projects contain 22,294 classes, of which 3,474 classes are unit tests. Overall, there are 275,602 methods in the system, of which 35,746 are on test classes.
This means, about 16% of the classes and 13% of the methods are related to tests. Since this seems to be a rather small number, I’ll keep the test code in the analysis even so the code may have different general properties.
To get an impression how classes are distributed over packages and projects, let’s look at the following plot.
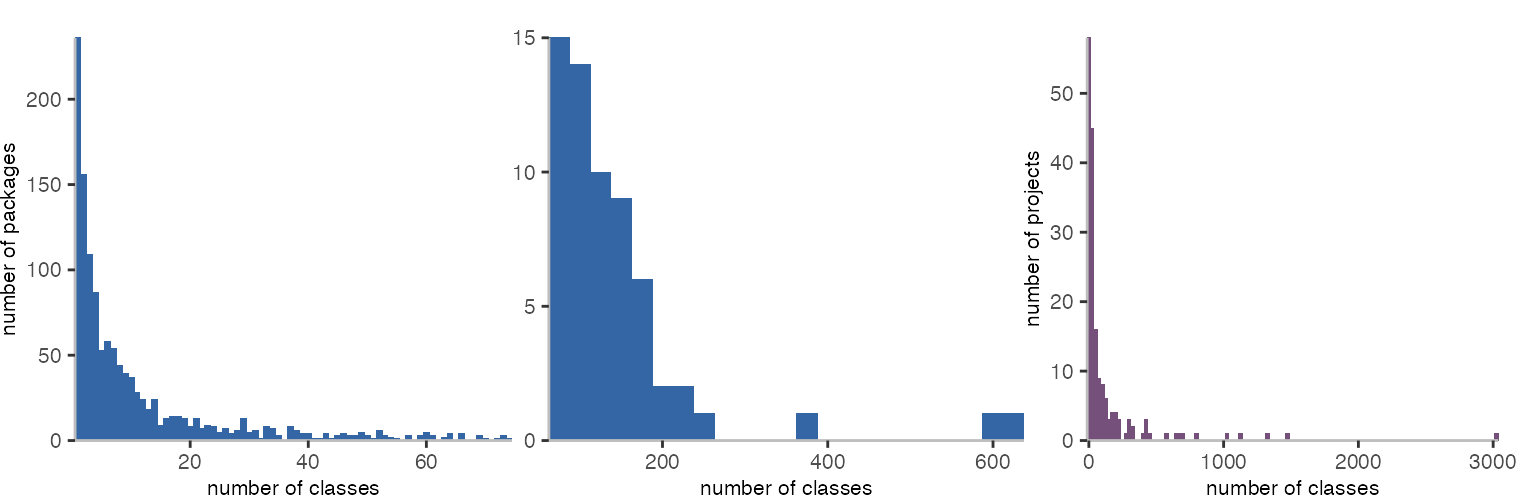
The first two graphs are histograms that show how many packages have a specific number of classes in them. We only record something if there’s a method, and a method needs a class. So, there are no packages without any classes. But there are plenty of packages with only 1 class. The number of packages that have high number of classes decreases rapidly. The second histogram shows all packages that have 75 or more classes, and we see there are two packages with around 600 classes: Bloc, Brick.
The third histogram looks at the same data but this time by project. A project can consist of multiple packages, but it turns out, there are many projects with very few classes, and only very few projects with many classes. To make these details better visible, the second and third histogram uses a bin size of 25 instead of 1.
When looking at the following plots, we see that the results look a bit different for methods.
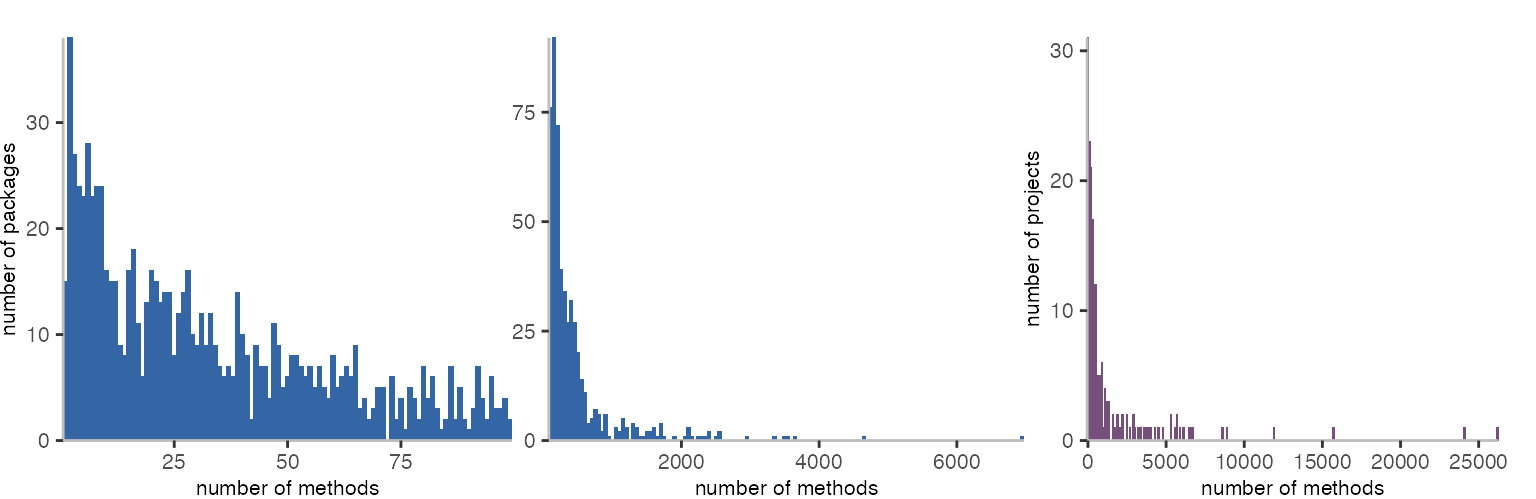
The first histogram (on the left) shows how many packages have 1, 2, and up to 99 methods in them. There seem to be about 15 packages with just a single method in them. And about 40 with 2 methods. Interestingly, the number of methods per package seems to show fewer similarities to the power law or pareto distribution than the number of classes.
Looking at the second histogram, which only considers the packages with 100 or more methods, we see a shape more similar to the power law.
When looking at the data at the granularity of projects, in the third histogram, we see many projects with very few methods, and only very few projects with many methods.
In this corpus, the projects Bloc, Glamorous Toolkit, SmaCC, and Spec all have more than 10,000 methods.
Structure of Classes
Let us assume for the rest of this post that this is a single code base. In Pharo, it would feel like a single code base anyway, since everything is in the image and can be accessed and modified easily.
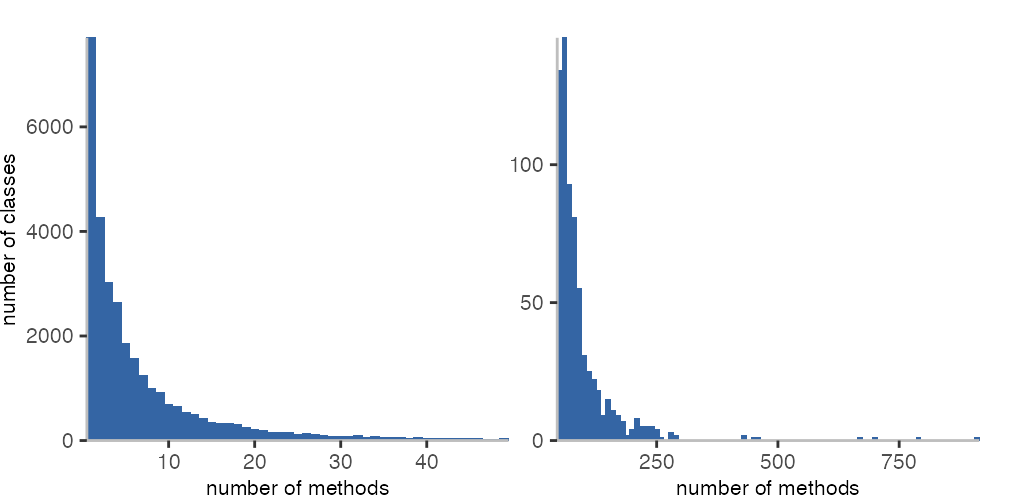
The two histograms above show the number of classes that have a particular number of methods. On the left, we see all class with fewer than 50 methods. Turns out, a lot of classes have a single method, and even though there are considerably fewer, there are quite a number of classes with 40 to 50 methods. In the histogram on the right, with a bin size of 10, we see that there are still plenty of classes with 50 to 100 methods, after which we then find fewer and fewer classes. The classes Morph, Object, and VBNetParser have each more than 700 methods, and thus, have the most methods.
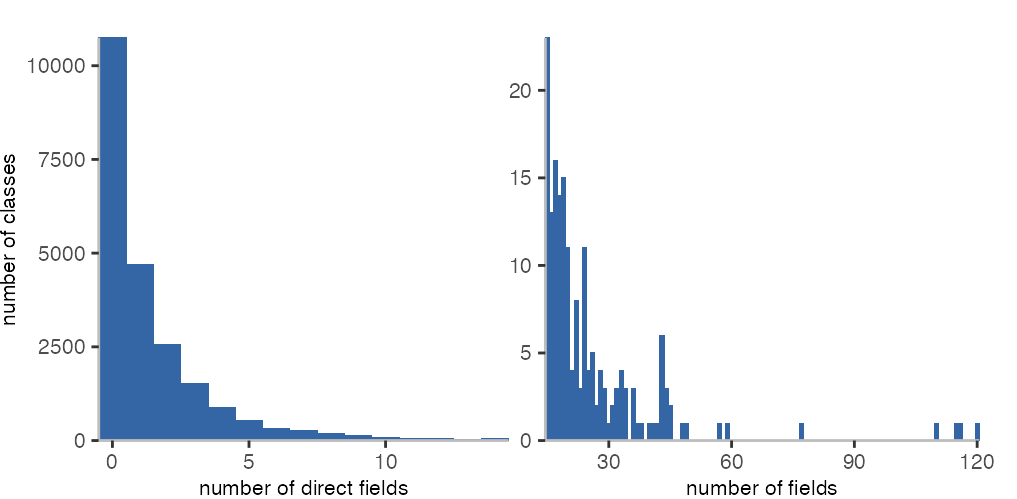
The histograms above show how many classes have a specific number fields that they directly declare. For comparison below, we’ll look at the total number of fields of a class, considering all fields of its superclasses.
For direct fields, we see that may classes do not have any fields, but plenty of them have some fields. In the histogram on the right, we see quite a number of classes with 15 or more fields (177 in total). The classes with more than 100 methods are PRPillarGrammar, PRPillarGrammarOld, PPYAMLGrammar, and FamixGenerator.
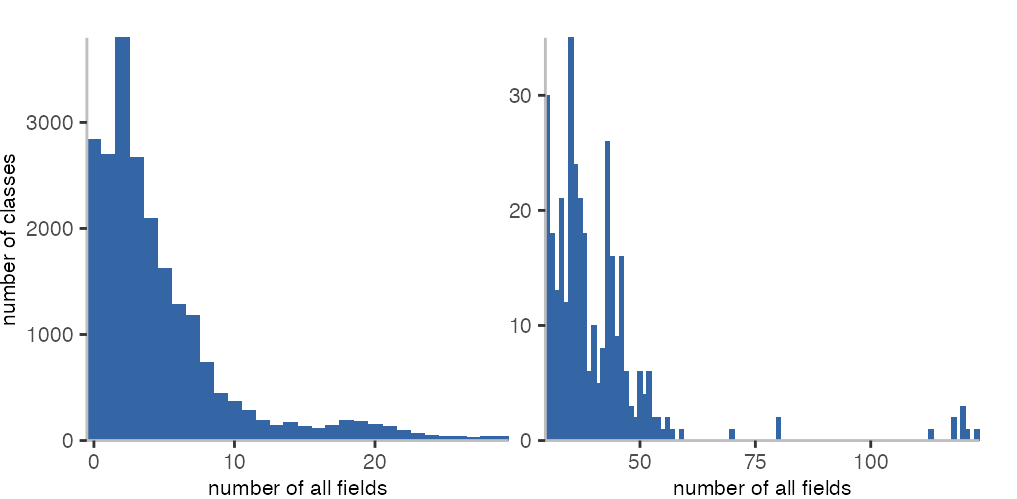
When considering all fields, including the ones in the superclass hierarchy, things look a little different. On the left, we see the number of classes that have fewer than 30 fields. Since we now count the classes from the superclass hierarchy, we see there’s a spike at three fields. For classes with 30 or more fields in total, in the histogram on the right, we see a few more spikes, but at a smaller level. The class with the most fields is PPYAMLGrammar and has 123 fields.
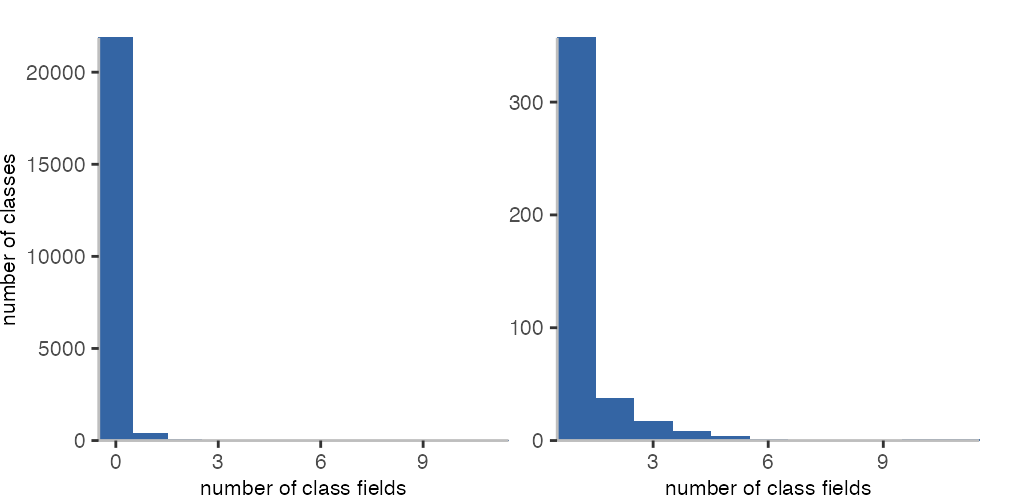
When it comes to class fields, the situation looks very different. Only 357 classes have one class field, and only 69 have more than one.
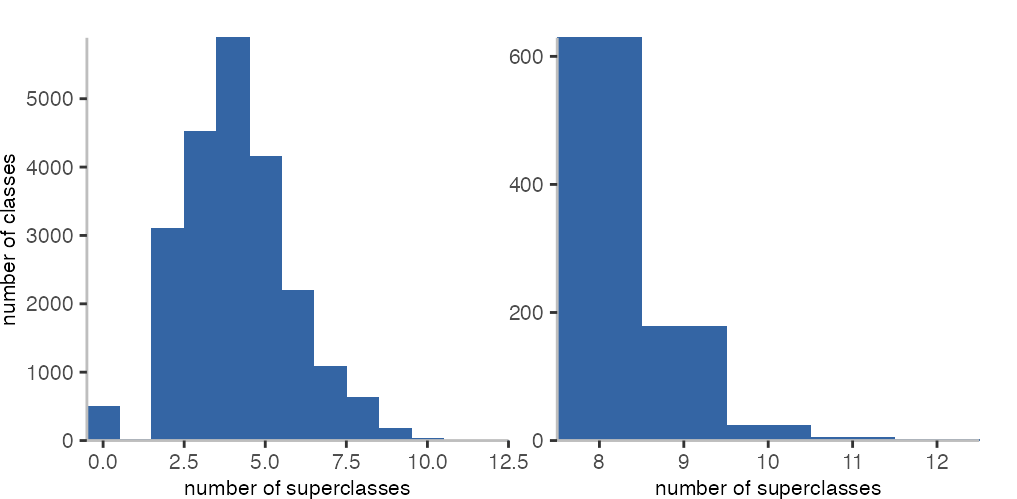
Since the number of fields depends on the superclass hierarchy, let’s have a look at the numbers for using inheritance.
The data looks a bit strange. We have few classes that have no superclass. This is a quirk in Pharo’s reflection system. These classes are not classic classes but traits. The few classes that have a single superclass are bit special, and reflect Pharo’s metalevel architecture. The most important one is Object. Its superclass is ProtoObject, where the hierarchy terminates. The other classes are what can be considered dynamic proxies, used for intercepting message sends/method calls.
Only few hierarchies turn out to be deep, which includes widgets and some test classes with 11 or 12 superclasses.
Structure of Methods
After looking at classes, let’s investigate the methods a bit closer.
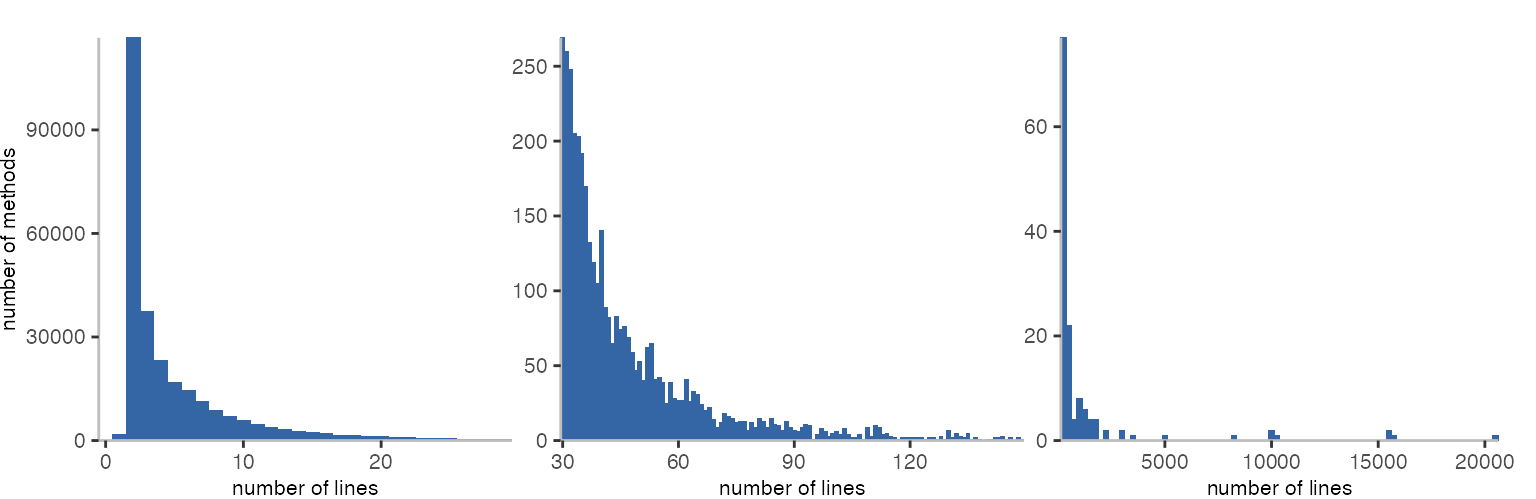
There’s indeed one method in a mock class that has no code. Not sure what’s going on there, but the method might simply not be a source method. I didn’t check. Though, there are 1797 methods with one line of code. First this seemed a little strange, too, but since Pharo considers method signatures as part of the method, it’s essentially empty methods. With this, it’s unsurprising that most methods have 2 lines, which includes accessors and all kind of other short methods.
If I recall correctly, Smalltalkers advice against methods with more than 6 or 7 lines. From the data distribution, the advice seems to be widely ignored. At least, there doesn’t seem to be a major step after 6-7 lines. There are 29 methods with more than 1,000 lines. The 9 methods with more than 5,000 lines seem to all carry various kind of data, things like JSON and JavaScript strings.
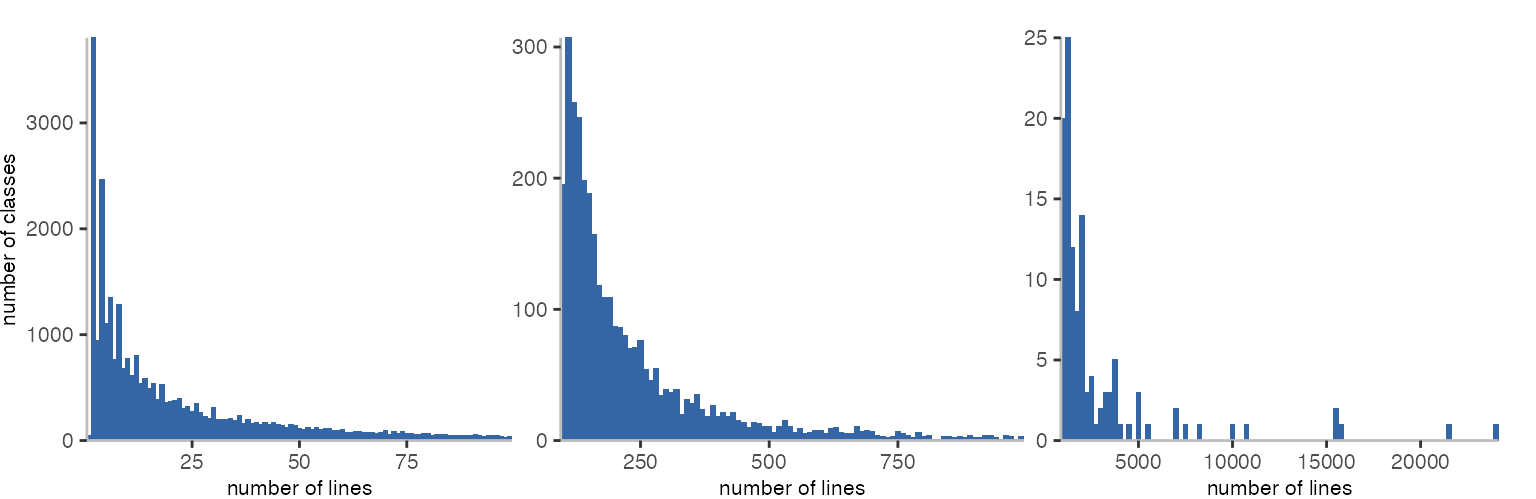
Looking at the lines of code by aggregating them per class reveals a mostly similar picture. Many tiny classes, and few large classes.
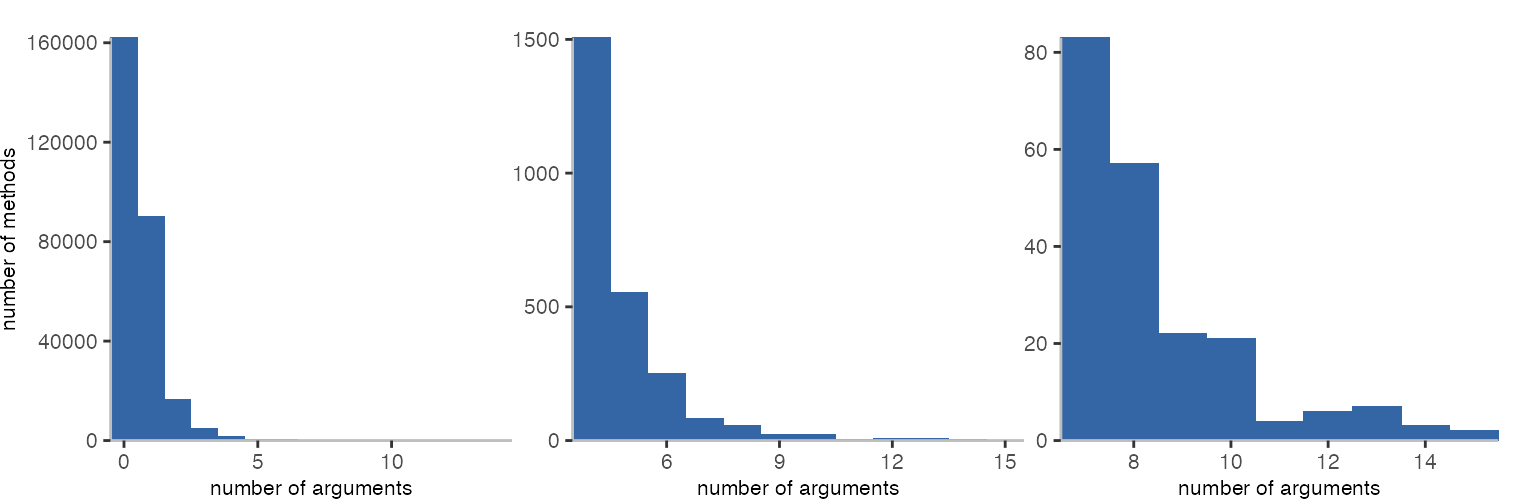
When looking at the number of arguments a method takes, we see a huge number not taking any at all (the receiver is not considered). About half of the methods has 1 argument, which seems plausible considering setters have one argument. The two methods with 15 arguments are methods to test the bytecode compiler.
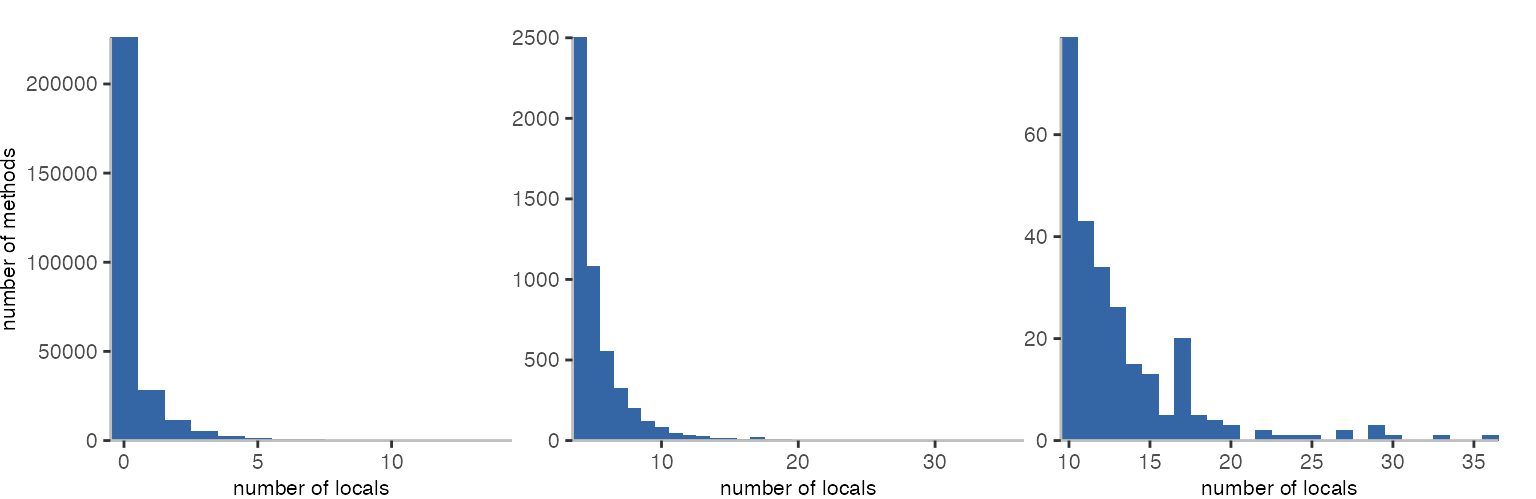
A lot of methods don’t have any local variables. Probably not surprising given the number of getters and setters why may assume. And, it seems people don’t actually go all out when it comes to local variables. 36 variables seem sufficient for everyone, and the particular method seems to rotate an elliptical arc, thus, implements a somewhat complex algorithm.
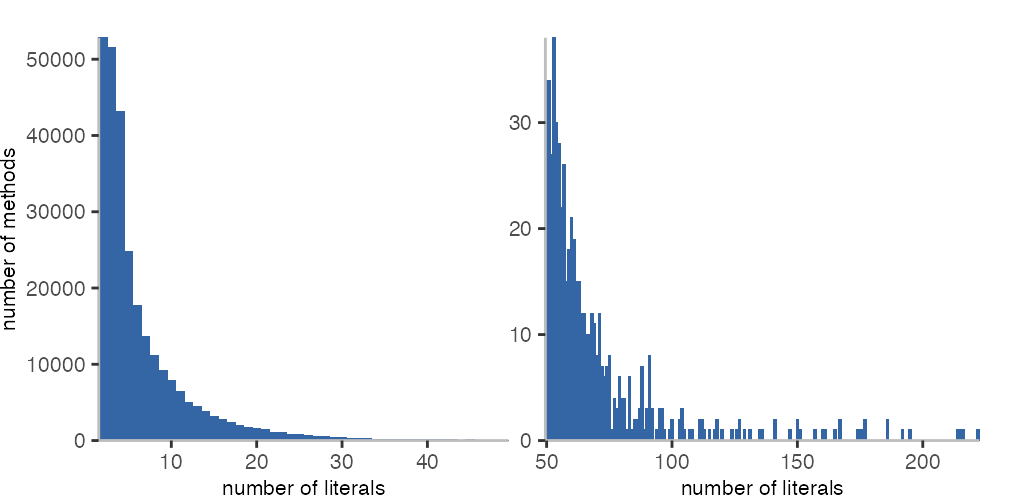
Finally, let’s have a look at the number of literals per method. Literals include any kind of numbers, constants, and constructs that have a specific syntax in the language, e.g., arrays. However, it also includes the names of methods, which are used for the message sends. Thus, it somewhat correlates with the number of message sends a method may possibly have. Though, that’s probably not a perfect correlation because of the other kinds of literals as well as all kind of optimizations in the bytecode set.
Conclusion
Ok, so, what to do with this data? I am not quite sure yet. Though, there are a few bits and pieces in here that are interesting. And, since I recently started generating large code bases to assess the performance of cold code, i.e., interpreter speed, I think some of these bits will allow me to generate more “natural” code.
Other details suggest to have a good look at various optimizations classic interpreters do. For example, SOMns optimizes the accessor methods to object fields already, and thus avoids a full method/function call for them. Not sure whether that’s an optimization applied by many languages, though, HotSpot does it under the term “fast accessor methods”.
Would also be interesting to see how these numbers compare across languages. Python and Ruby come to mind as similar class-based dynamic languages.
There might be more to gain from this data, but that’s for another day.
For suggestions, comments, or questions, find me on Twitter @smarr.
Appendix
The following table contains the details on the projects included in this analysis.
| Project | Commit | URL |
|---|---|---|
| DrTests | 010eb9b | https://github.com/juliendelplanque/DrTests |
| Mustache | 728feda | https://github.com/noha/mustache |
| PetitParser | bd108b9 | https://github.com/moosetechnology/PetitParser |
| Pillar | 4d8a285 | https://github.com/pillar-markup/pillar |
| Seaside | e0c73a5 | https://github.com/SeasideSt/Seaside |
| Spec2 | 988c6d7 | https://github.com/pharo-spec/Spec |
| PolyMath | 473b0b0 | https://github.com/PolyMathOrg/PolyMath |
| Telescope | 8c47cfc | https://github.com/TelescopeSt/TelescopeCytoscape |
| Voyage | f4f9d28 | https://github.com/pharo-nosql/voyage |
| Bloc | a8c7ecb | https://github.com/pharo-graphics/Bloc |
| DataFrame | 7422404 | https://github.com/PolyMathOrg/DataFrame |
| Roassal2 | d65a87a | https://github.com/ObjectProfile/Roassal2 |
| Roassal3 | 167de2d | https://github.com/ObjectProfile/Roassal3 |
| Moose | fc8fb07 | https://github.com/moosetechnology/Moose |
| GToolkit | e3c98fc | https://github.com/feenkcom/gtoolkit |
| Iceberg | 7e78a75 | https://github.com/pharo-vcs/iceberg |