 I head the
I head the
The Cost of Safety in Java
Overhead of Null Checks, Array Bounds, and Class Cast Exceptions in GraalVM Native Image
Normally, I’d say, please do not try this at home. Though, this time, it’s more appropriate:
Warning: Do not do this in production!
It’s fine to do it at home and for curiosity, but we are all better off when our programming languages are safe.
For context, with the increased interest in Rust, people are arguing again about all kind of programming languages and their performance characteristics with respect to safety. One of the widely used ones is Java of course, which I am using for my research.
With GraalVM’s native image at hand, it seemed like a good opportunity to assess roughly how much performance goes into some of Java’s memory safety features. I am using native image ahead-of-time compilation here, because JVMs like HotSpot can do all kind of nice tricks to remove more overhead at run time than other statically compiled languages can. To level the playing field, let’s stick to static ahead-of-time compilation for this experiment.
Memory Safety in Java
Let’s start with a few examples of how Java ensures memory safety.
Implicit Null Checks
When accessing an object in Java, it first makes sure that the object is
an actual object and not null.
This means, when the following code tries to access the Element object e,
we have an implicit null check,
which prevents us from accessing arbitrary memory.
public Object testImplicitIsNull(Element e) {
return e.getValue();
}
To illustrate this, here the relevant part of the compiler graph:
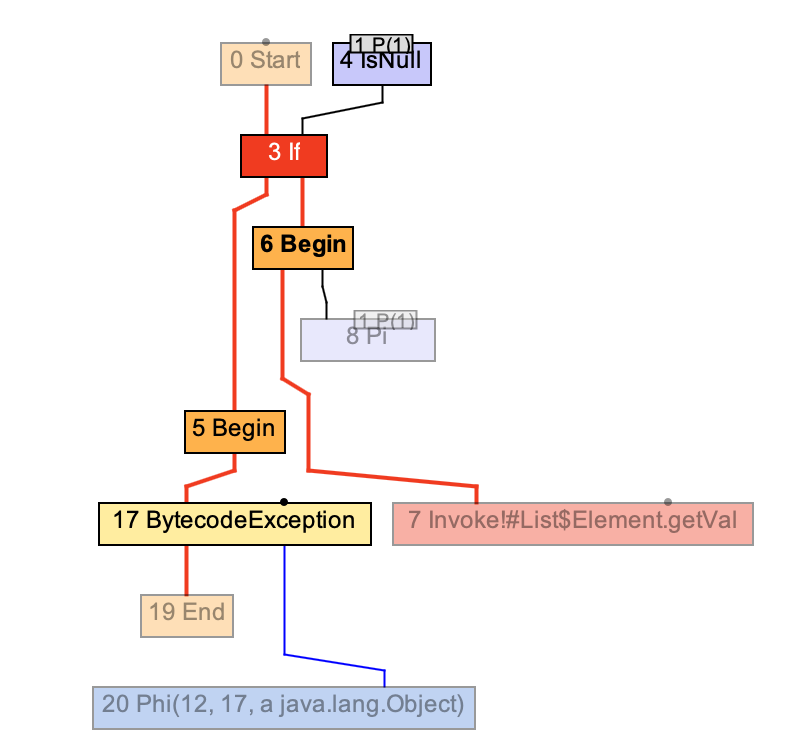
We can see an If node, which is not in our Java code.
This If is the implicit null check. In the graph,
we also see a IsNull node that access the method’s parameter 1, indicated as P(1) in the graph. The true branch on the left of the If leads to a BytecodeException node, which in later compiler phases would be mapped to a classic NullPointerException.
Implicit Array Bounds Checks
When accessing arrays, Java similarly checks that we are not accessing the array outside of its boundaries. Again, trying to make sure that we do not access arbitrary memory. The following method is thus compiled to include an implicit bounds check, too:
public Object boundsCheck(Object[] array, int index) {
return array[index];
}
This time, let’s look at the complete compiler graph for the method:
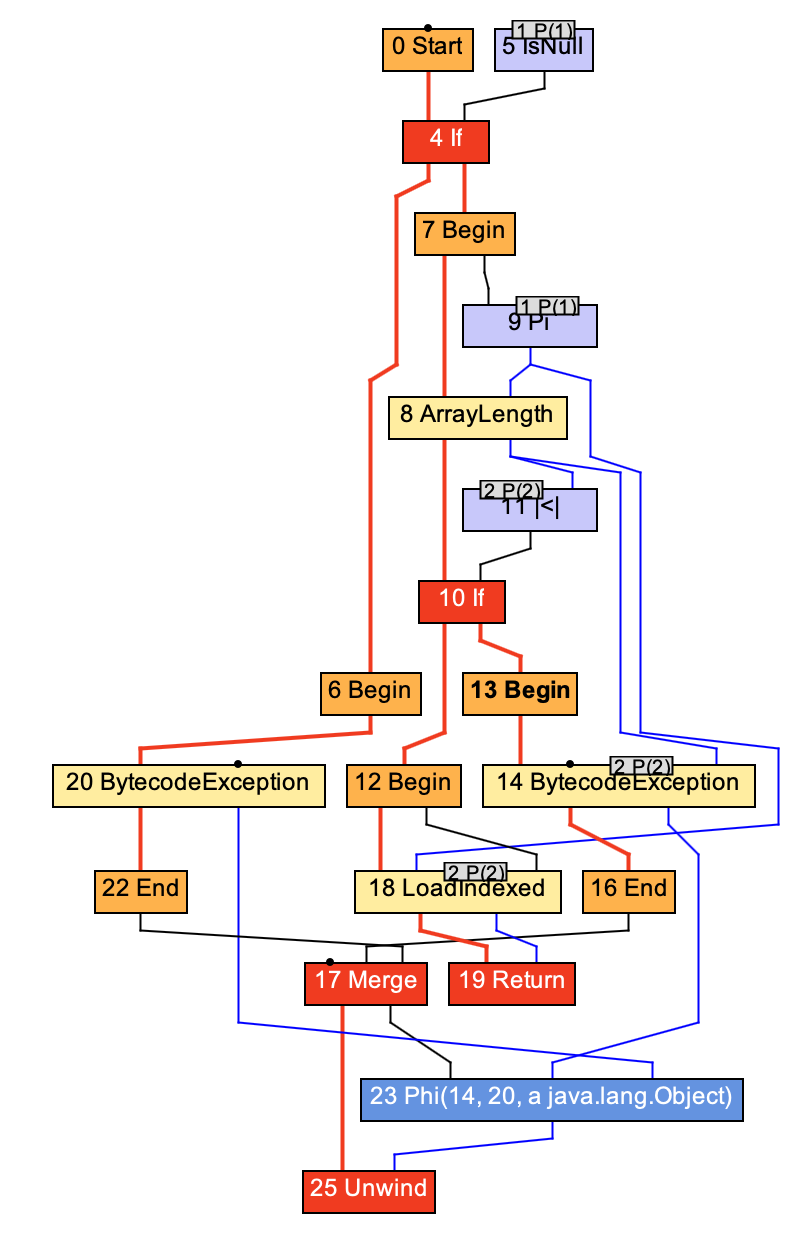
Reading it from the top, we notice again the null check.
And indeed, since arrays are objects, we of course also need to
check that we have a proper object first.
A little further down, we see the ArrayLength node, which reads the length of the array, and then we see a |<| node, which checks that the second parameter to our method, our index is smaller than the array length but not smaller than zero. Only if that’s the case, we will read from the array with the LoadIndexed node.
For the case that we have an out-of-bounds index, the compiler turns the BytecodeException node into a ArrayIndexOutOfBoundsException exception.
Other safety features I won’t go into include for instance,
casts causing a ClassCaseException to avoid unsafe accesses.
Removing Safety
For this experiment, I implemented two new compiler phases for Graal.
Both essentially look for the BytecodeException nodes and remove
these exception branches from the compiler graphs.
In the Graal compiler, this is relatively straight forward.
We can find the If node from the BytecodeException node
and set it’s condition to always be either true of false
depending in which branch the BytecodeException node was,
ensuring that it can never be activated.
Graal can then remove this branch as it is not reachable anymore.
I used two phases so that I catch the exception branches very early on the compilation process in the first phase. And then essentially do the same thing a second time after some higher level nodes have been lowered into groups of nodes which may again contain these safety checks.
At the moment, I don’t distinguish different types of bytecode exceptions, of which there are a few, which means, the result is indeed inherently unsafe, and even changes Java semantics, possibly breaking programs. Some Java code may, and in practice indeed does, depend on these implicit exceptions. Thus, the compiler phases are only applied to application code for which I know that it is safe.
The code can be found here: graal:unsafe-java.
Experiments
The first set of experiments is a set of benchmarks that were designed to assess cross-language performance, the Are We Fast Yet benchmarks. They contain 9 microbenchmarks, and 5 slightly larger ones to cover various common language features of object-oriented languages.
On some of these benchmarks, it doesn’t make any difference at all, since the benchmarks are dominated by other aspects. Though, even for larger benchmarks, it can reduce run time by 3-10%.
| Run time | ||
|---|---|---|
| change | ||
| CD |  |
-4% |
| DeltaBlue |  |
-10% |
| Havlak |  |
-3% |
| Json |  |
-5% |
| Richards |  |
-10% |
| Bounce |  |
-7% |
| List |  |
-3% |
| Mandelbrot |  |
0% |
| NBody |  |
0% |
| Permute |  |
-4% |
| Queens | |
-28% |
| Sieve |  |
-22% |
| Storage |  |
0% |
| Towers |  |
-5% |
To emphasize: these benchmarks are designed to compare performance across languages, and to identify possible compiler optimizations. They are very likely not going to translate directly to the application you may care about.
For the full results, see ReBenchDB:are-we-fast-yet.
Unsafe Truffle Interpreters
For me, there are a few “applications” I care deeply about at the moment. My research focuses on speeding up interpreters, especially in the GraalVM/Truffle ecosystems.
TruffleSOM, a research language, has two different type of interpreters. A Truffle-style abstract syntax tree (AST) interpreter as well as a interpreter based on bytecodes.
For the AST interpreter, focusing just on the larger benchmarks, we see the following results:
| Run time | ||
|---|---|---|
| change | ||
| DeltaBlue |  |
-5% |
| GraphSearch |  |
-7% |
| Json |  |
-5% |
| NBody |  |
-5% |
| PageRank |  |
-8% |
| Richards |  |
-6% |
So, the changes are in the 5-8% range. For an interpreter, that is a significant improvement. Typically any improvement here is hard won. (Full Results: TruffleSOM: AST interp.)
Let’s also look at the bytecode interpreter:
| Run time | ||
|---|---|---|
| change | ||
| DeltaBlue |  |
-8% |
| GraphSearch |  |
-12% |
| Json |  |
-10% |
| NBody |  |
-14% |
| PageRank |  |
-16% |
| Richards |  |
-14% |
Here, we see a higher benefit, in the 8-16% range. This is likely because of the access to the bytecode array, which now doesn’t do the bounds check any longer. Since this is a very common operation, it gives a good extra bonus. (Full Results: TruffleSOM: BC interp.)
Since TruffleSOM is a research language, fairly small in comparison to other languages, let’s have a look at the impact on TruffleRuby, which is a mature implementation of Ruby, and Ruby is a quite a bit more complex language.
Here I cherry picked a couple of larger Ruby applications just to keep it brief:
| Run time | ||
|---|---|---|
| change | ||
| AsciidoctorConvertTiny |  |
-5% |
| AsciidoctorLoadFileTiny |  |
-5% |
| ActiveSupport |  |
-10% |
| LiquidCartParse |  |
-10% |
| LiquidCartRender |  |
-1% |
| LiquidMiddleware |  |
-17% |
| LiquidParseAll |  |
-9% |
| LiquidRenderBibs |  |
-7% |
| OptCarrot |  |
-9% |
Here we see a range of 1-17% improvements, but the measurements are somewhat noisy. (Full Results: ReBenchDB: TruffleRuby)
The big question is now: are our interpreters correct enough to do away with the extra safety layer? It’s likely not a good idea, no…
For questions or comments, please find me on Twitter.