 I head the
I head the
Effortless Language Servers
Ever since my blog post in 2016, I have wanted a good language server for SOM and Newspeak. Though, I didn’t really have the time to implement more than a few features.
Then in 2019, colleagues from HPI and Oracle showed that one can get a language server basically for free. Though, their approach has one drawback: the language server needs to execute the code you’re editing. Otherwise, you won’t get much info in your language-server-protocol-enabled IDE.
For language implementers like myself, this is however still a great approach, because I need to make almost no changes to my language implementation to support this. So, a language implemented on top of the Truffle framework will benefit almost out of the box.
What if I Had Just a Few Days To Build a Language Server?
If I had just a few hours, I can get a language server for my language that enables code navigation, code completion, and an outline view. Though, the info shown in my IDE is basically only as good as my test coverage.
So, how far could we push it if I had, let’s say a few days, to implement a language server for my programming language? How would we go about it, and what would I need, trying to keep my implementation effort minimal?
A Good Set of Features
What are the most relevant features for a dynamic programming language? Some of my personal favorites can be seen in the following screenshot:
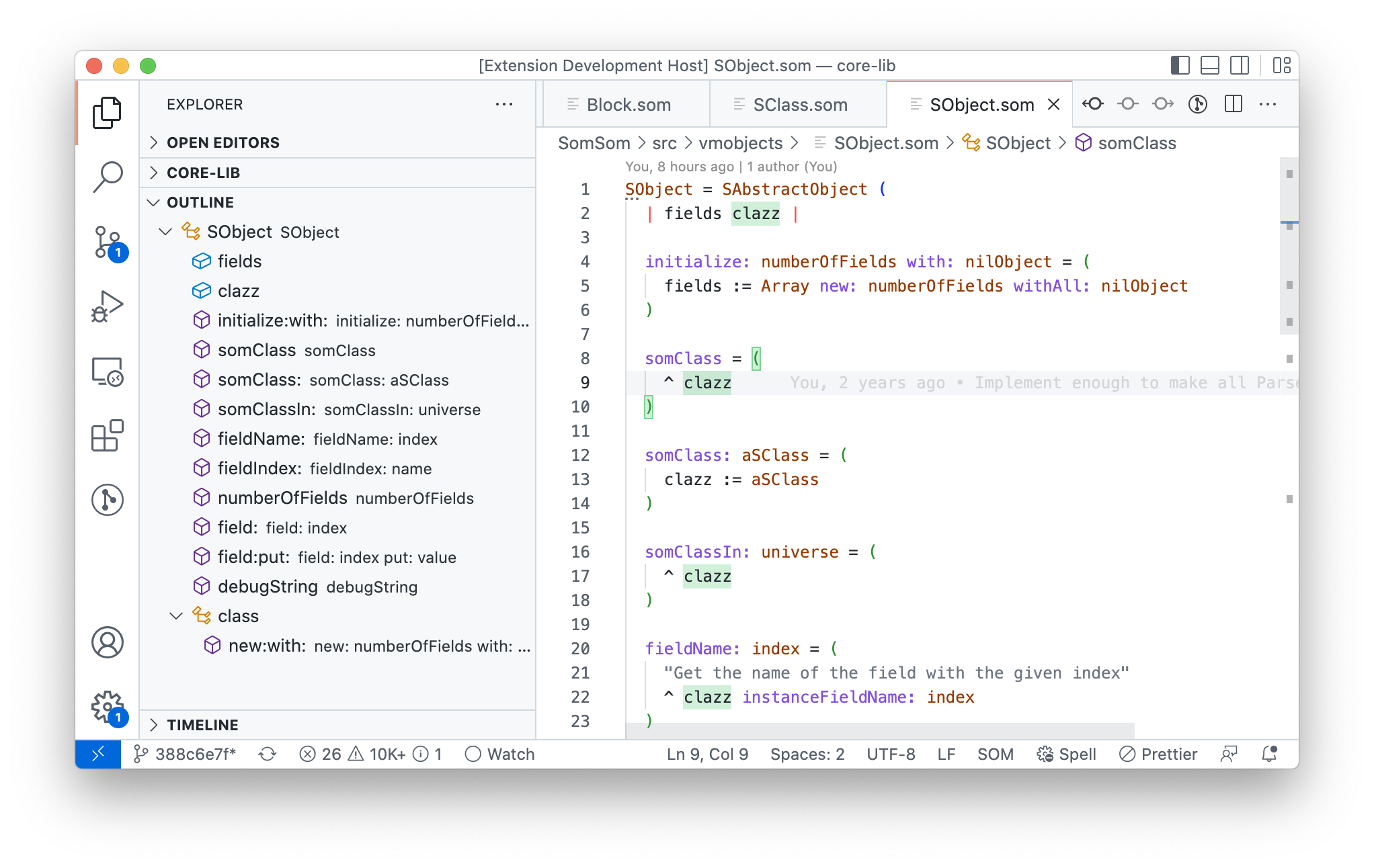
They include:
- semantic highlighting
- an outline view
- highlighting semantically correct references to the currently selected identifier
- jump to definition
- code completion
- signature details on hover
- syntax errors
- and basic linting
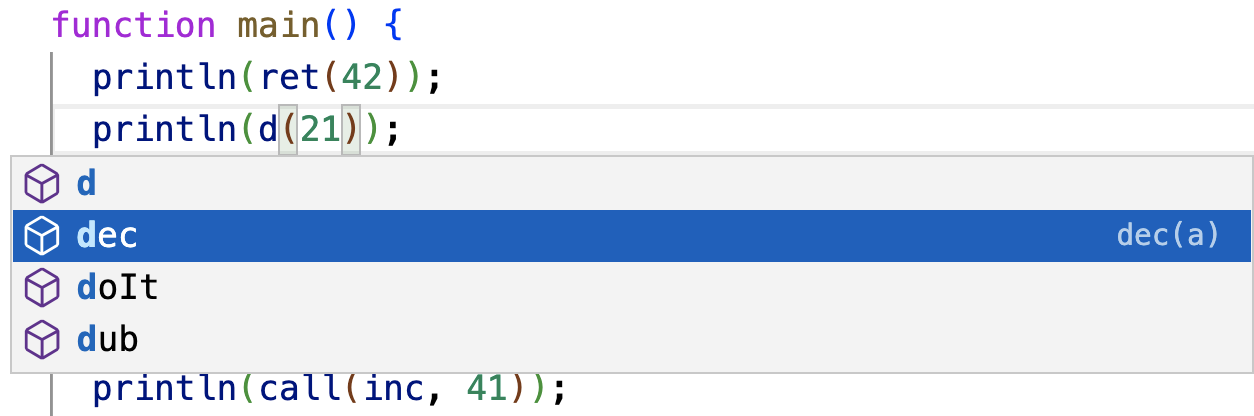
Two more screenshots, with code completion, and correctly highlighting a syntax error:

What Does It Take To Implement a Language Server for This?
Turns out, it requires me just to capture a few bits of structural information, most of which my language implementation already collects anyway.
With our approach of a language-agnostic language server framework, it’s as simple as collecting this data during parsing. For the languages we tried, it took barely 500 to 1,000 lines of fairly simple code.
What’s the Trick?
For the details, I’d recommend to read our paper. To keep it brief here: we designed a way to represent language structures in a language-agnostic way that is sufficient to satisfy the various requests supported by the language server protocol.
This is in essence one step further from the language server protocol: making not just the same language server usable in many IDEs, but many parts of the language server reusable for different languages, too!
Our prototype works well for dynamic languages implemented in Java. We have one language that uses ANTLR for parsing, as well as two languages with custom parsers.
If you want to give it a spin, head over to our GitHub repository: smarr/effortless-language-servers.
For questions, you can find us on Twitter, or attend our talk at the Dynamic Language Symposium in December.
Abstract
With the wide adoption of the language server protocol, the desire to have IDE-style tooling even for niche and research languages has exploded. The Truffle language framework facilitates this desire by offering an almost zero-effort approach to language implementers to providing IDE features. However, this existing approach needs to execute the code being worked on to capture much of the information needed for an IDE, ideally with full unit-test coverage.
To capture information more reliably and avoid the need to execute the code being worked on, we propose a new parse-based design for language servers. Our solution provides a language-agnostic interface for structural information, with which we can support most common IDE features for dynamic languages.
Comparing the two approaches, we find that our new parse-based approach requires only a modest development effort for each language and has only minor tradeoffs for precision, for instance for code completion, compared to Truffle’s execution-based approach.
Further, we show that less than 1,000 lines of code capture enough details to provide much of the typical IDE functionality, with an order of magnitude less code than ad hoc language servers. We tested our approach for the custom parsers of Newspeak and SOM, as well as SimpleLanguage’s ANTLR grammar without any changes to it. Combining both parse and execution-based approaches has the potential to provide good and precise IDE tooling for a wide range of languages with only small development effort. By itself, our approach would be a good addition to the many libraries implementing the language server protocol to enable low-effort implementations of IDE features.
- Execution vs. Parse-Based Language Servers: Tradeoffs and Opportunities for Language-Agnostic Tooling for Dynamic Languages
S. Marr, H. Burchell, F. Niephaus; In Proceedings of the 18th Symposium on Dynamic Languages, DLS'22, p. 14, ACM, 2022. - Paper: HTML, PDF
- DOI: 10.1145/3563834.3567537
- Appendix: online appendix
-
BibTex:
bibtex
@inproceedings{Marr:2022:LSP, abstract = {With the wide adoption of the language server protocol, the desire to have IDE-style tooling even for niche and research languages has exploded. The Truffle language framework facilitates this desire by offering an almost zero-effort approach to language implementers to providing IDE features. However, this existing approach needs to execute the code being worked on to capture much of the information needed for an IDE, ideally with full unit-test coverage. To capture information more reliably and avoid the need to execute the code being worked on, we propose a new parse-based design for language servers. Our solution provides a language-agnostic interface for structural information, with which we can support most common IDE features for dynamic languages. Comparing the two approaches, we find that our new parse-based approach requires only a modest development effort for each language and has only minor tradeoffs for precision, for instance for code completion, compared to Truffle's execution-based approach. Further, we show that less than 1,000 lines of code capture enough details to provide much of the typical IDE functionality, with an order of magnitude less code than ad hoc language servers. We tested our approach for the custom parsers of Newspeak and SOM, as well as SimpleLanguage's ANTLR grammar without any changes to it. Combining both parse and execution-based approaches has the potential to provide good and precise IDE tooling for a wide range of languages with only small development effort. By itself, our approach would be a good addition to the many libraries implementing the language server protocol to enable low-effort implementations of IDE features.}, acceptancerate = {0.4}, appendix = {https://github.com/smarr/effortless-language-servers}, author = {Marr, Stefan and Burchell, Humphrey and Niephaus, Fabio}, blog = {https://stefan-marr.de/2022/10/effortless-language-servers/}, booktitle = {Proceedings of the 18th Symposium on Dynamic Languages}, day = {7}, doi = {10.1145/3563834.3567537}, html = {https://stefan-marr.de/papers/dls-marr-et-al-execution-vs-parse-based-language-servers/}, keywords = {Comparison ExecutionTime LanguageServerProtocol MeMyPublication ParseTime myown}, location = {Auckland, New Zealand}, month = dec, note = {(acceptance rate 40%)}, pages = {14}, pdf = {https://stefan-marr.de/downloads/dls22-marr-et-al-execution-vs-parse-based-language-servers.pdf}, publisher = {ACM}, series = {DLS'22}, title = {Execution vs. Parse-Based Language Servers: Tradeoffs and Opportunities for Language-Agnostic Tooling for Dynamic Languages}, year = {2022}, month_numeric = {12} }