 I head the
I head the
Squeezing a Little More Performance Out of Bytecode Interpreters
Earlier this year, Wanhong Huang, Tomoharu Ugawa, and myself published some new experiments on interpreter performance. We experimented with a Genetic Algorithm to squeeze a little more performance out of bytecode interpreters. Since I spent much of my research time looking for ways to improve interpreter performance, I was quite intrigued by the basic question behind Wanhong’s experiments: which is the best order of bytecode handlers in the interpreter loop?
The Basics: Bytecode Loops and Modern Processors
Let’s start with a bit of background. Many of today’s widely used interpreters use bytecodes, which represent a program as operations quite similar to processor instructions. Though, depending on the language we are trying to support in our interpreter, the bytecodes can be arbitrarily complex, in terms of how they encode arguments, but also in terms of the behavior they implement.
In the simplest case, we would end up with an interpreter loop that looks roughly like this:
1
2
3
4
5
6
7
8
9
10
11
12
13
uint8_t bytecode = { push_local, push_local, add, /* ... */ }
while (true) {
uint8_t bytecode = bytecodes[index];
index += /* ... */;
switch (bytecode) {
case push_local:
// ...
case add:
// ...
case call_method:
// ...
}
}
switch/case Interpreter Loop.Here, push_local and add are much simpler than any call_method bytecode.
Depending on the language that we try to implement, push_local is likely just a few processor instructions, while call_method might be significantly more complex, because it may need to lookup the method, ensure that arguments are passed correctly, and ensure that we have memory for local variables for the method that is to be executed.
Since bytecodes can be arbitrarily complex,
S. Brunthaler
distinguished between high abstraction-level interpreters
and low abstraction-level ones.
High abstraction-level interpreters
do not spend a lot of time on the bytecode dispatch, but low abstraction-level
ones do, because their bytecodes are comparably simple, and have often just a handful of processor instructions. Thus, low abstraction-level interpreters
would benefit most from optimizing the bytecode dispatch.
A classic optimization of the bytecode dispatch is threaded code interpretation, in which we represent a program not only using bytecodes, but with an additional array of jump addresses. This optimization is also often called direct threaded code. It is particularly beneficial for low abstraction-level interpreters but applied more widely.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
uint8_t bytecode = { push_local, push_local, add, /* ... */ }
void* targets = { &&push_local, &&push_local, &add, /* ... */ }
push_local:
// ...
void* target = targets[index];
index += /* ... */
goto *target;
add:
// ...
void* target = targets[index];
index += /* ... */
goto *target;
call_method:
// ...
void* target = targets[index];
index += /* ... */
goto *target;
With this interpreter optimization, we do not have the explicit while loop.
Instead, we have goto labels for each bytecode handler
and each handler has a separate copy of the dispatch code, that is the goto jump instruction.
This helps modern processors in at least two ways:
-
it avoids an extra jump to the top of the loop at the end of each bytecode,
-
and perhaps more importantly, we have multiple dispatch points instead of a single one.
This is important for branch prediction.
In our first loop, a processor would not be able to predict
where a jump is going, because the switch normally translates to a single jump
that goes to most, if not all bytecodes.
Though, when we have the jump at the end of a bytecode handler,
we may only see a subset of bytecodes,
which increases the chance that the processor can predict the jump correctly.
Unfortunately, modern processors are rather complex. They have limits for instance for how many jump targets they can remember. They may also end up combining the history for different jump instructions, perhaps because they use an associative cache based on the address of the jump instruction. They have various different caches, including the instruction cache, into which our interpreter loop ideally fits for best performance. And all these things may interact in unexpected ways.
For me, these things make it pretty hard to predict the performance of a bytecode loop for a complex language such as JavaScript or Ruby.
And if it’s too hard to understand, why not try some kind of machine learning. And that’s indeed what Wanhong and Tomoharu came up with.
Towards an Optimal Bytecode Handler Ordering
With all the complexity of modern processors, Wanhong and Tomoharu observed that changing the order of bytecode handlers can make a significant difference for the overall performance of an interpreter. Of course, this will only make a difference if our interpreter indeed spends a significant amount of time in the bytecode loop and the handler dispatch itself.
When looking at various interpreters, we will find most of them use a natural order. With that I mean, the bytecode handlers are in the order of the numbers assigned to each bytecode. Other possible orders could be a random order, or perhaps even an order based on the frequency of bytecodes or the frequency of bytecode sequences. Thus, one might simply first have the most frequently used bytecodes, and then less frequently used ones, perhaps hoping that this means the most used instructions fit into caches, or help the branch predictor in some way.
The goal of our experiments was to find out whether we can use a Genetic Algorithm to find a better ordering so that we can improve interpreter performance. We use a genetic algorithm to create new orders of bytecode handlers by producing a crossover from two existing orderings that combine both with a few handlers being reordered additionally, which adds mutation into the new order. The resulting bytecode handler order is then compile into a new interpreter for which we measure the run time of a benchmark. With a Genetic Algorithm, one can thus generate variations of handler orders that over multiple generations of crossover and mutation may evolve to a faster handler order.
I’ll skip the details here, but please check out the paper below for the specifics.
Results on a JavaScript Interpreter
So, how well does this approach work? To find out, we applied it to the eJSVM, a JavaScript interpreter that is designed for resource-constraint devices.
In the context of resource-constraint embedded devices, it may make sense to tailor an interpreter to a specific applications to gain best performance. Thus we started by optimizing the interpreter for a specific benchmark on a specific machine. To keep the time needed for the experiments manageable, we used three Intel machines and one Raspberry Pi with an ARM CPU. In many ways, optimizing for a specific benchmark is the best-case scenario, which is only practical if we can deploy a specific application together with the interpreter. Figure 1 shows the results on benchmarks from the Are We Fast Yet benchmark suite. We can see that surprisingly large improvements. While the results depend very much on the processor architecture, every single benchmark sees an improvement on all platforms.
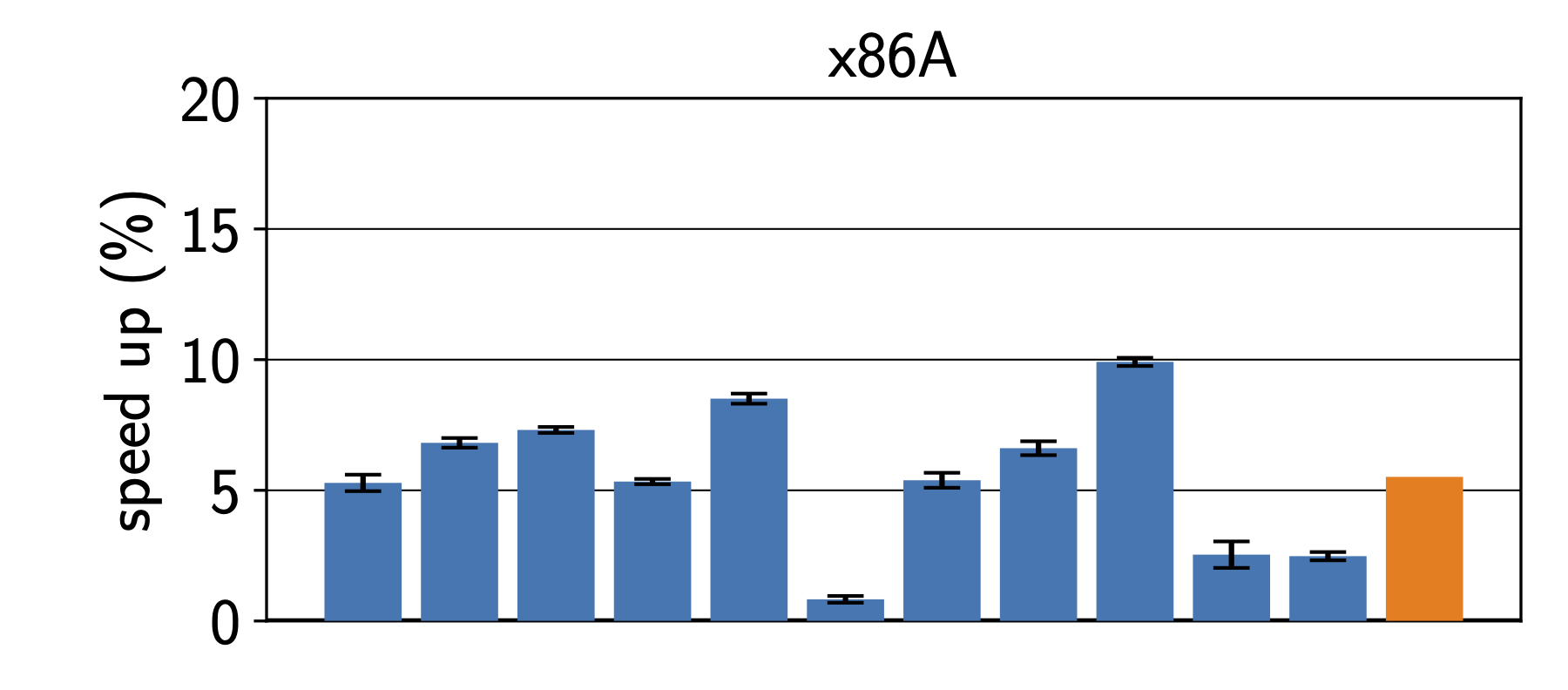
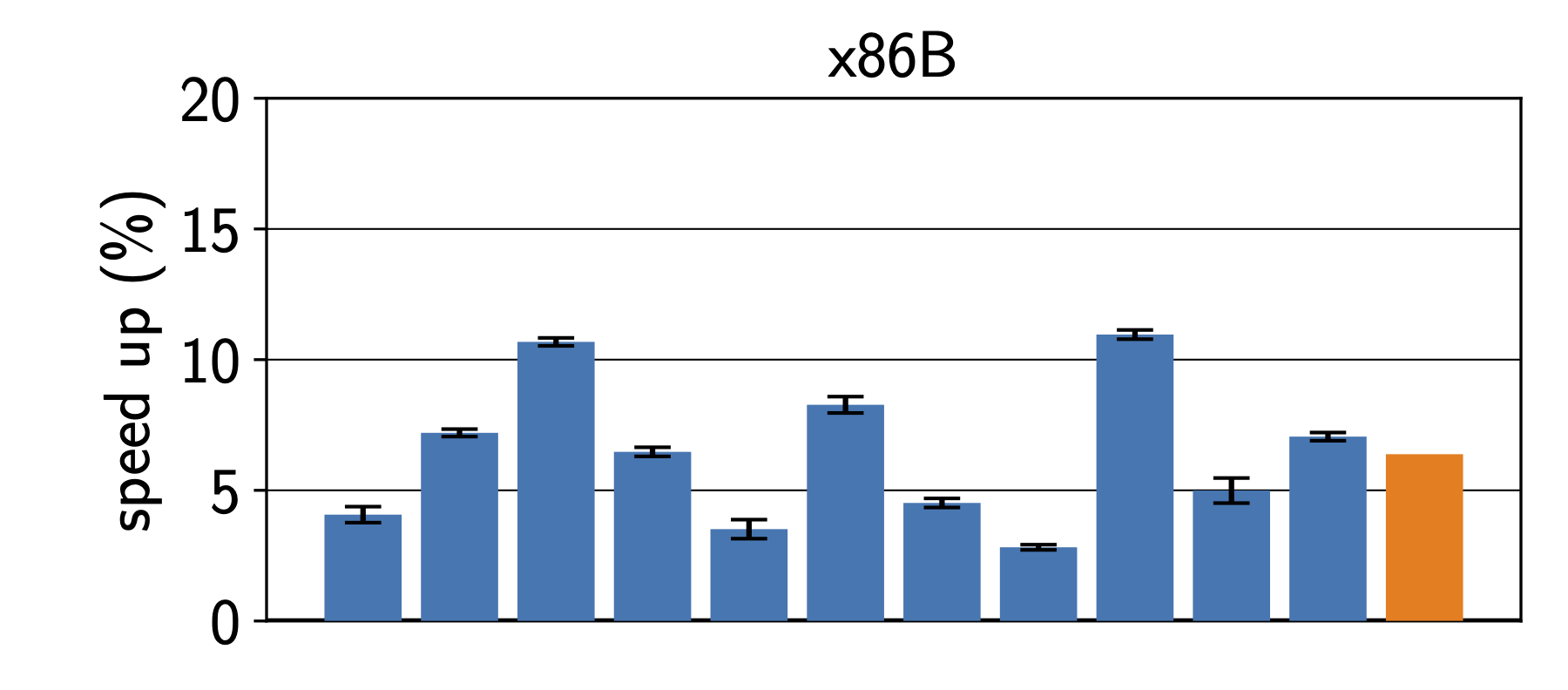
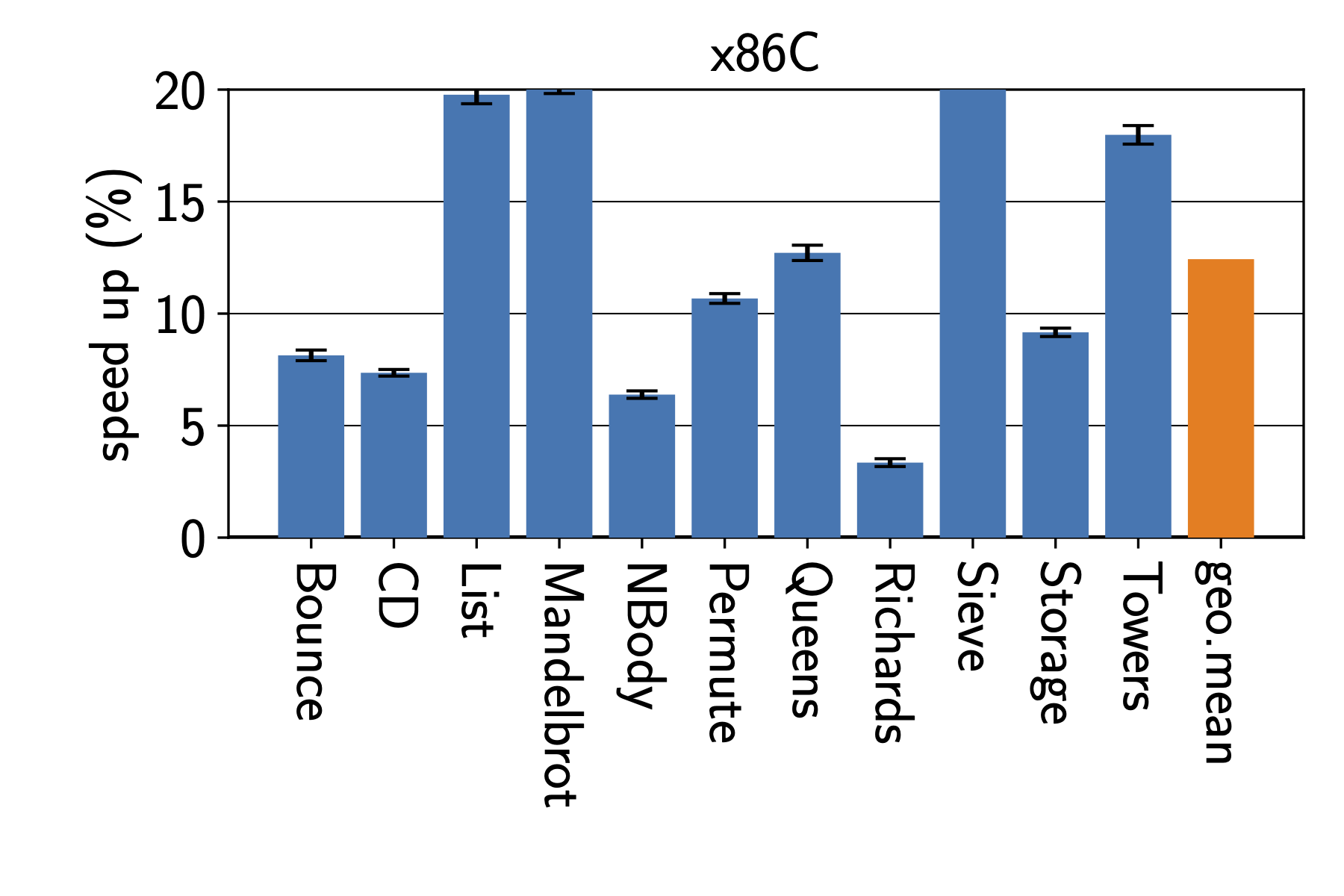
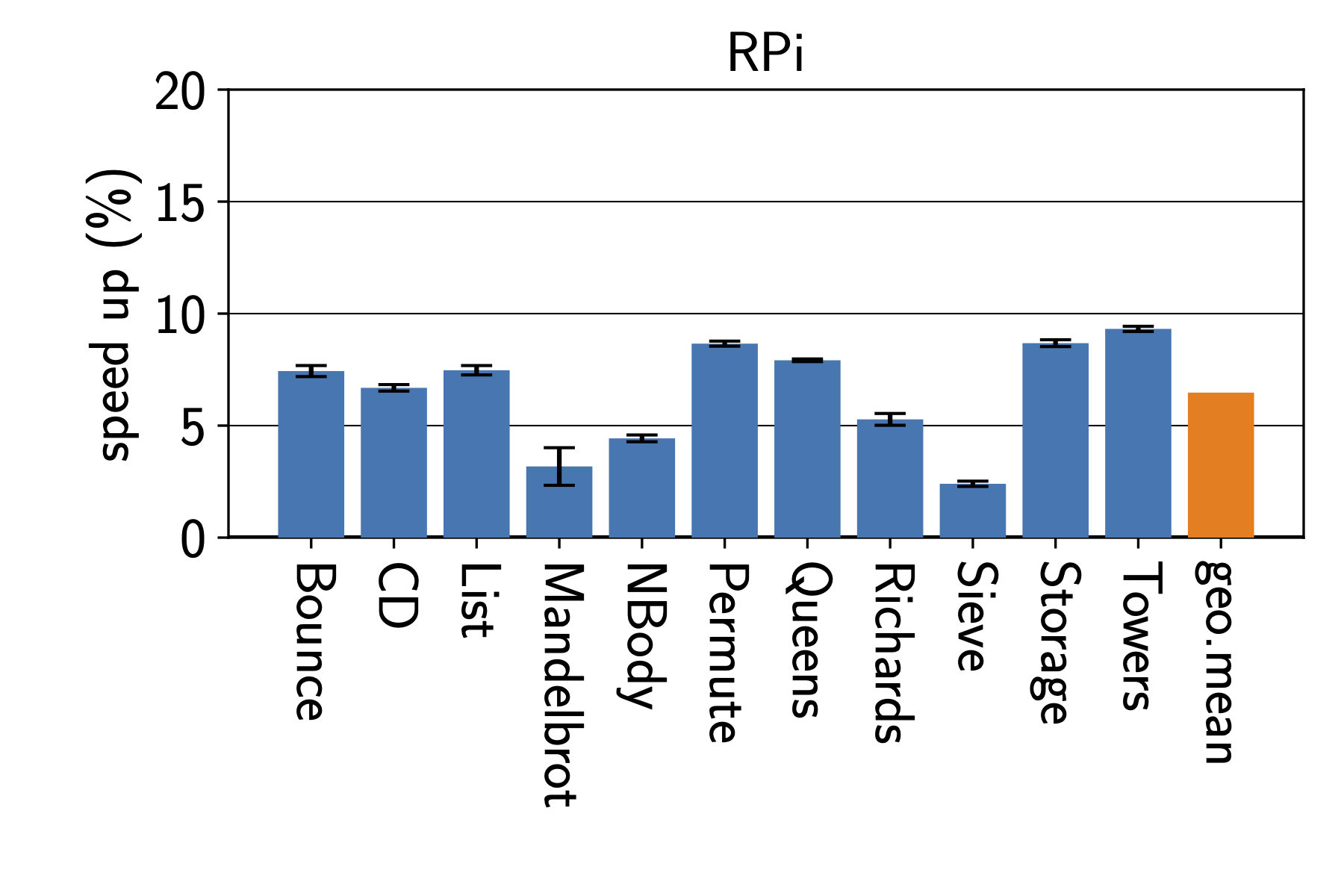
Unfortunately, we can’t really know which programs user will run on our interpreters for all scenarios. Thus, we also looked at how interpreter speed improves when we train the interpreter on a single benchmark. Figure 2 shows how the performance changes when we train the interpreter for a specific benchmark. In the top left corner, we see the results when training for the Bounce benchmark. While Bounce itself sees a 7.5% speedup, the same interpreter speeds up the List benchmark by more than 12%. Training the interpreter on the Permute benchmark gives how ever much less improvements for the other benchmarks.
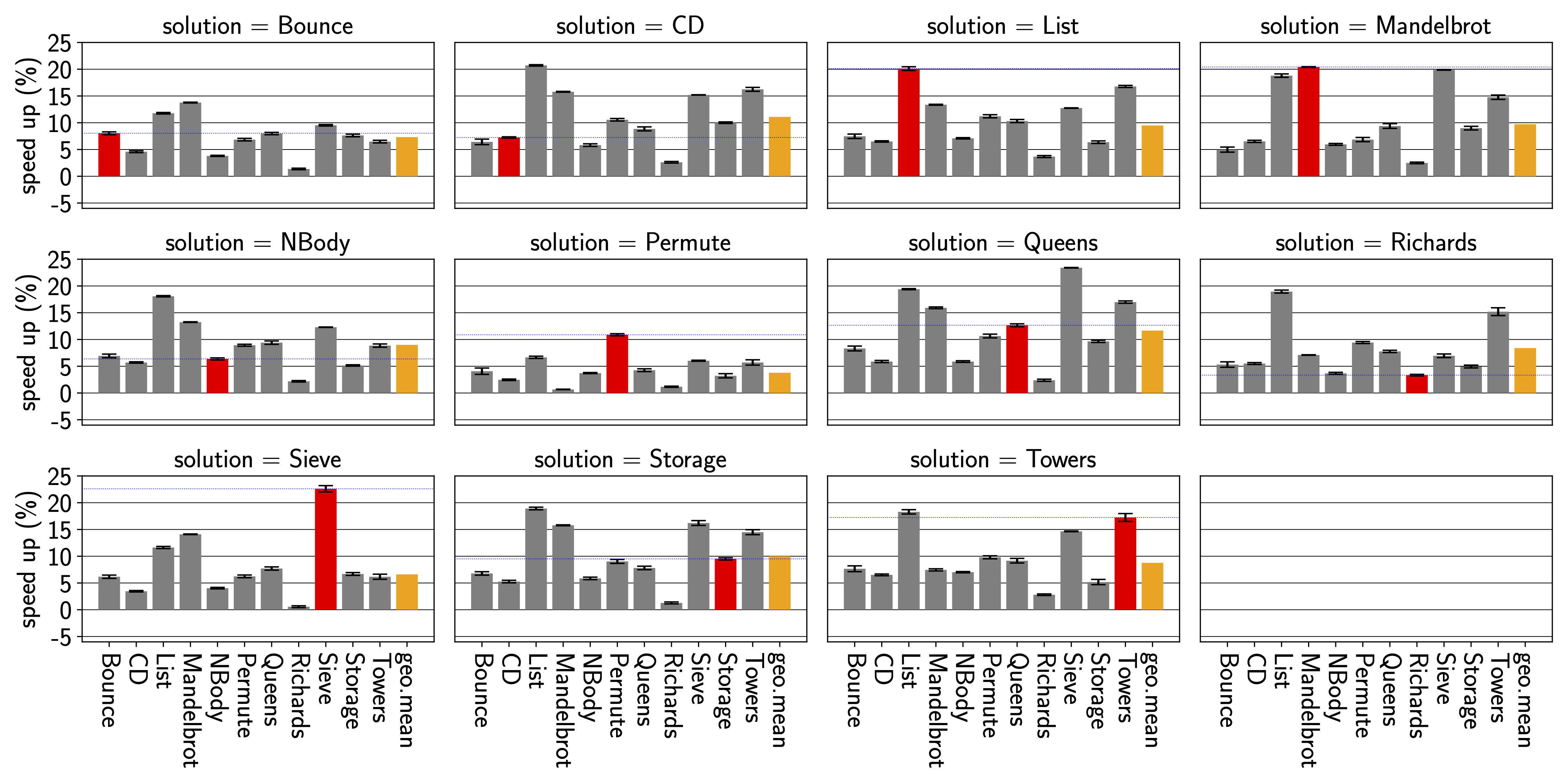
In the paper, we look at a few more aspects including which Genetic Algorithm works best and how portable performance is between architectures.
Optimizing Bytecode Handler Order for other Interpreters
Reading this blog post, you may wonder how to best go about experimenting with your own interpreter. We also briefly tried optimizing CRuby, however, we unfortunately did not yet manage to find time to continue, but we found a few things that one needs to watch out for when doing so.
First, you may have noticed that we used a relatively old versions of GCC.
For eJSVM, these gave good results and did not interfere with our reordering.
However, on CRuby and with newer GCCs, the compiler will start to reorder
basic blocks itself, which makes it harder to get the desired results.
Here flags such as -fno-reorder-blocks
or -fno-reorder-blocks-and-partition may be needed.
Clang didn’t seem to reorder basic blocks in the interpreter loop.
As a basic test of how big a performance impact might be,
I simply ran a handful of random bytecode handler orders, which I would normally would expect to show some performance difference, likely a slowdown. Though, for CRuby I did not see a notable performance change, which suggests that bytecode dispatch may not be worth optimizing further. But it’s a bit early to tell conclusively at this point. We should give CPython and others a go, but haven’t gotten around to it just yet.
Conclusion
If you care about interpreter performance, maybe it’s worth to take a look at the interpreter loop and see whether modern processors deliver better performance when bytecode handlers get reordered.
Our results suggest that it can give large improvements when training for a specific benchmark. There is also still a benefit for other benchmarks that we did not train for, though, it depends on how similar the training benchmark is to the others.
For more details, please read the paper linked below, or reach out on Twitter @smarr.
Abstract
Interpreter performance remains important today. Interpreters are needed in resource constrained systems, and even in systems with just-in-time compilers, they are crucial during warm up. A common form of interpreters is a bytecode interpreter, where the interpreter executes bytecode instructions one by one. Each bytecode is executed by the corresponding bytecode handler.
In this paper, we show that the order of the bytecode handlers in the interpreter source code affects the execution performance of programs on the interpreter. On the basis of this observation, we propose a genetic algorithm (GA) approach to find an approximately optimal order. In our GA approach, we find an order optimized for a specific benchmark program and a specific CPU.
We evaluated the effectiveness of our approach on various models of CPUs including x86 processors and an ARM processor. The order found using GA improved the execution speed of the program for which the order was optimized between 0.8% and 23.0% with 7.7% on average. We also assess the cross-benchmark and cross-machine performance of the GA-found order. Some orders showed good generalizability across benchmarks, speeding up all benchmark programs. However, the solutions do not generalize across different machines, indicating that they are highly specific to a microarchitecture.
- Optimizing the Order of Bytecode Handlers in Interpreters using a Genetic Algorithm
W. Huang, S. Marr, T. Ugawa; In The 38th ACM/SIGAPP Symposium on Applied Computing (SAC '23), SAC'23, p. 10, ACM, 2023. - Paper: PDF
- DOI: 10.1145/3555776.3577712
-
BibTex:
bibtex
@inproceedings{Huang:2023:GA, abstract = {Interpreter performance remains important today. Interpreters are needed in resource constrained systems, and even in systems with just-in-time compilers, they are crucial during warm up. A common form of interpreters is a bytecode interpreter, where the interpreter executes bytecode instructions one by one. Each bytecode is executed by the corresponding bytecode handler. In this paper, we show that the order of the bytecode handlers in the interpreter source code affects the execution performance of programs on the interpreter. On the basis of this observation, we propose a genetic algorithm (GA) approach to find an approximately optimal order. In our GA approach, we find an order optimized for a specific benchmark program and a specific CPU. We evaluated the effectiveness of our approach on various models of CPUs including x86 processors and an ARM processor. The order found using GA improved the execution speed of the program for which the order was optimized between 0.8% and 23.0% with 7.7% on average. We also assess the cross-benchmark and cross-machine performance of the GA-found order. Some orders showed good generalizability across benchmarks, speeding up all benchmark programs. However, the solutions do not generalize across different machines, indicating that they are highly specific to a microarchitecture.}, author = {Huang, Wanhong and Marr, Stefan and Ugawa, Tomoharu}, blog = {https://stefan-marr.de/2023/06/squeezing-a-little-more-performance-out-of-bytecode-interpreters/}, booktitle = {The 38th ACM/SIGAPP Symposium on Applied Computing (SAC '23)}, doi = {10.1145/3555776.3577712}, isbn = {978-1-4503-9517-5/23/03}, keywords = {Bytecodes CodeLayout EmbeddedSystems GeneticAlgorithm Interpreter JavaScript MeMyPublication Optimization myown}, month = mar, pages = {10}, pdf = {https://stefan-marr.de/downloads/acmsac23-huang-et-al-optimizing-the-order-of-bytecode-handlers-in-interpreters-using-a-genetic-algorithm.pdf}, publisher = {ACM}, series = {SAC'23}, title = {{Optimizing the Order of Bytecode Handlers in Interpreters using a Genetic Algorithm}}, year = {2023}, month_numeric = {3} }