 I am working at the
I am working at the Modellkonsistenz
Stefan Marr
Hasso-Plattner-Institut, Universität Potsdam,
Potsdam 14482, Germany
stefan.marr at hpi.uni-potsdam.de
Zusammenfassung. An fast allen Punkten im Softwareentwicklungsprozess kommt man mit einer Vielzahl von Modellen in Berührung. Je größer die Software, desto größer und komplexer werden auch die Modelle. Eine manuelle Konsistenzsicherung wird somit zunehmend ineffizient. Um das Problem der Inkonsistenz zwischen diesen Modellen strukturiert angehen zu können, wird der Begriff der Inkonsistenz, Ursachen, typische Inkonsistenzen in UML-Modellen und ein Verfahren für den Umgang mit Inkonsistenzproblemen näher betrachtet. Im Anschluss daran werden Ansätze untersucht, welche als Grundlage für eine Werkzeugunterstützung zur Inkonsistenzerkennung in UML-Modellen dienen können. Nach einem Überblick über verschiedene Ansätze zur Inkonsistenzerkennung wird ein Verfahren, welches auf Konsistenzregeln aufbaut, etwas näher betrachtet und das Potenzial für UML-Werkzeuge aufgezeigt.
1 Einleitung
In der Softwareentwicklung wurden schon immer Modelle zu den unterschiedlichsten Zwecken eingesetzt. Um Anforderungen zu erfassen, Datenstrukturen darzustellen, Geschäftsprozesse zu modellieren oder auch um die Struktur des Softwaresystems selbst beschreiben zu können. Seit sich die UML in vielen Bereichen als Industriestandard durchgesetzt hat, kommt zum bisher überwiegend dokumentierenden Charakter der Modelle auch verstärkt der programmierende Aspekt hinzu. Modelle dienen vermehrt zur vollständigen Beschreibung von ausführbarem Verhalten. Insbesondere mit Ansätzen wie dem Model Driven Development wird so der Bedarf nach konsistenten Modellen verstärkt.
Widerspruchsfreie Modelle werden aber auch ohne ihre Verwendung als Grundlage für eine werkzeuggestützte Generierung von Artefakten benötigt. Letztendlich dienen sie immer als Arbeitsgrundlage für die weitere Entwicklung z.B. zur Kommunikation oder als Spezifikation für eine Implementierung. Somit haben Fehler bzw. Inkonsistenzen in Modellen einen erheblichen Einfluss auf die Qualität der auf ihrer Grundlage erstellten Software.
Da Modelle jedoch zu den verschiedensten Zwecken erstellt und dafür die verschiedensten Darstellungen gewählt werden, ist ein Konsistenzerhalt zwischen den Modellen alles andere als einfach. Für die Kommunikation mit einem Kunden kann bei der Vorstellung der Systemarchitektur ein Modell in einer Ad-hoc-Notation mit diversen Piktogrammen und einer sehr abstrakten, weniger technischen Darstellung verwendet werden. Der Austausch zwischen den Architekten erfolgt hingegen z.B. mit einem FMC-Aufbaudiagramm, da hier die Semantik eindeutig ist und die Notation mit nur wenigen Grundkenntnissen verwendet werden kann. Auf der Implementierungsebene wird hingegen UML verwendet, um die Struktur des Systems z.B. mit Klassendiagrammen bis ins letzte Detail genau darstellen zu können.
Aus dieser Vielfalt resultieren die verschiedensten Probleme, die den Konsistenzerhalt zwischen den Modellen erschweren. Einerseits variiert die verwendete Modellierungssprache und damit der Grad der Formalität und Ausdrucksstärke des Modells. Andererseits unterscheiden sich die Modelle in Blickwinkel und Fokus, die sie auf das System haben. Sie stellen somit nicht alle und unterschiedliche Aspekte dar.
Das Beispiel zeigt, dass allein bei der Beschreibung der Softwarearchitektur schon großes Potenzial für Inkonsistenzen gegeben ist. Dazu kommen natürlich die diversen anderen Aspekte von Software, die ebenfalls modelliert werden müssen und jeweils eigene, spezielle Darstellungsformen erfordern. Letztendlich kommt es dabei auf verschiedenen Ebenen zu Problemen. So sollen die Diagramme einerseits korrekt im Sinne ihre Sprachsyntax sein, wie dies z.B. bei UML mithilfe der Wellformedness-Regeln definiert ist und andererseits sollen Widersprüche in der modellierten Struktur und im beschriebenen Verhalten ausgeschlossen werden.
Eine manuelle Konsistenzprüfung der Modelle ist daher mit erheblichem Aufwand verbunden und wird momentan aufgrund der damit verbundenen Kosten nur in kritischen Bereichen eingesetzt. Eine Automatisierung der Konsistenzprüfung mithilfe von Werkzeugen integriert in die Modellierungsumgebung hätte jedoch das Potenzial die Qualität der Modelle in Bezug auf den Grad der Konsistenz nachhaltig zu verbessern. Wodurch sich wiederum die Qualität der auf diesen Modellen aufbauenden Software entsprechend erhöht.
Bevor Ansätze für solch eine Werkzeugunterstützung näher betrachtet werden können, müssen jedoch erst einmal Inkonsistenz allgemein, ihre Ursachen und typische Probleme näher betrachtet werden. Anschließend wird ein allgemeiner Weg zum Umgang mit Inkonsistenzen dargestellt, um den Einfluss von Inkonsistenzen auf den Softwareentwicklungsprozess zu verdeutlichen. Daran schließt sich die Betrachtung verschiedener Ansätze für Werkzeugunterstützung an, wobei ein Ansatz zur Verwendung von Konsistenzregeln etwas genauer betrachtet wird, um aufzuzeigen, wie eine automatische Konsistenzprüfung in einem Modellierungswerkzeug funktionieren kann.
2 Inkonsistenz
Als Grundlage für die weiteren Betrachtungen soll die Definition für Inkonsistenz von Bashar Nuseibeh [1] dienen:
Eine Inkonsistenz tritt genau dann auf, wenn eine Konsistenzregel verletzt wird.
Aus dieser sehr grundlegenden Definition lässt sich zudem ableiten [3], dass zwischen einer Menge von Beschreibungen die definierten Beziehungen eingehalten werden müssen und sie andernfalls, als inkonsistent zu einander gelten. Diese Form der Definition wurde gewählt, um eine größtmögliche Flexibilität in der Entscheidung von Konsistenz zu haben. Dazu müssen aber auch entsprechende Konsistenzregeln definiert und so formuliert werden, dass sie überprüft werden können. Dies ist bei der Vielzahl von verwendeten Notationen eine entsprechend komplexe Aufgabe. Grundsätzlich gibt es mehrere Aspekte in der Softwareentwicklung für die solche Konsistenzregeln definiert werden können.
Angefangen mit der Projektebene besteht die Möglichkeit, durch z.B. die Vorgabe von bestimmten Modelltypen für bestimmte Probleme und einer vorgegebenen Reihenfolge der zu erstellenden Modelle schon mithilfe des Projektmanagements die Konsistenz verschiedener Modelle zu begünstigen. Geht man von hieraus weiter auf die Modellebene, kann über eine Regelung z.B. festgelegt sein, dass Verhalten nur auf Elementen beschrieben werden soll, deren Struktur und Typ bereits im Vorfeld in gewissem Umfang beschrieben wurden. Auf der Sprachebene gibt es zumeist bereits Regeln, die die Syntax bestimmen und somit die Verwendung von Sprachmitteln zu einem gewissen Grad einschränken. Dies ist beispielhaft in Abb. 1 anhand einer OCL-Wellformedness-Regel für UML-Diagramme dargestellt. Regeln, die die Beziehungen zwischen Diagrammen einschränken, sind ebenso denkbar, um unter anderem die Referenzierungen zu den Modellelementen handhabbar zu halten, indem definiert wird welche Diagramme sich untereinander referenzieren dürfen und wie Redundanz vermieden wird.
Diese Regeln bieten für die Anwender viel Gestaltungsspielraum. So ermöglichen sie es u.a. domänenspezifische Aspekte zu berücksichtigen und Industriestandards festzulegen, um bspw. eine Konsistenz zwischen Modellen auch auf unternehmensübergreifender Ebene zu erreichen. Grundsätzlich ist festzustellen [3], dass diese Menge an Konsistenzregeln in großen Projekten ständig überarbeitet und angepasst werden muss, da diese Regeln nie für alle Probleme im Voraus aufgestellt werden können.
Problematisch ist es außerdem, eine geeignete Form für solche Regeln zu finden, in der auch die Konsistenz zwischen Modellen in beliebigen Sprachen beschrieben werden kann. In Abschnitt 3 werden Ansätze für die Definition von Regeln zur Konsistenz zwischen verschiedenen UML-Modellen und auch Modelltypen vorgestellt. Für die Angabe von Regeln zwischen sehr unterschiedlichen Modellierungssprachen reichen diese Ansätze jedoch nicht aus. So werden für die Beschreibung von Konsistenzbeziehungen zwischen natürlichsprachigen Spezifikationen und grafischen Modellierungssprachen, meist nur Regeln in natürlicher Sprache angeben, da die Ausdruckstärke der natürlichen Sprache zu groß ist, um sie in formalisierter Art und Weise erfassen und beschreiben zu können.
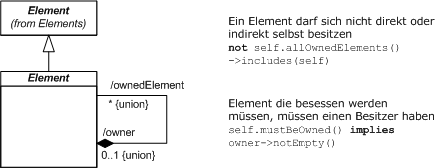 Abb. 1 UML-Wellformedness-Regel aus der Infrastructure im Package Abstraction [2], [21]
Abb. 1 UML-Wellformedness-Regel aus der Infrastructure im Package Abstraction [2], [21]Daraus ergibt sich eine mögliche Ursache für Inkonsistenzen, die in der unterschiedlichen Ausdruckstärke von verschiedenen Sprachen begründet liegt. Weitere mögliche Gründe für Inkonsistenzen werden im folgenden Abschnitt betrachtet.
2.1 Ursachen für Inkonsistenzen
Im Softwareentwicklungsprozess ist das Auftreten von Inkonsistenzen nicht vermeidbar und wird, wie in Abschnitt 2.3 gezeigt wird, nicht nur toleriert sondern teilweise sogar gewünscht. Die Gründe, die zu diesen Inkonsistenzen führen, sind vielfältig [13] und beruhen zu großen Teilen auf der notwendigen arbeitsteiligen Entwicklung.
Die verschiedenen beteiligten Entwickler haben natürlicherweise oft unterschiedliche Sichtweisen und Ansichten zu den auftretenden Problemen. Sie sprechen darüber hinaus andere Sprachen, sowohl zur verbalen Kommunikation als auch zur Modellierung und unterscheiden sich in der Qualifikation, geprägt durch Milieu, Herkunft und Ausbildung. Dazu kommen andere methodische Herangehensweisen und Denkansätze bei einer Problemlösung. Diese Unterschiede verfestigen sich letztendlich in den Modellen und führen zu Inkonsistenzen. Weitere Ursachen sind z.B., dass unterschiedliche Abschnitte des Entwicklungsprozesses durch die erstellten Modelle angesprochen werden sollen, überlappende oder disjunkte Aspekte adressiert werden und die technischen, ökonomischen und politischen Zielsetzungen unterschiedlich sind.
Unklare Anforderungen oder Lücken in der Spezifikation sind ebenso Ursachen, die zu unterschiedlichen Interpretationen führen und somit widersprüchliche Designentscheidungen verursachen können. Darüber hinaus birgt die Komplexität der Materie entsprechendes Fehlerpotenzial. Große, unübersichtliche Diagramme sind aufwendig in der Wartung und die vielfältigen und impliziten Zusammenhänge schwer in vollem Umfang zu erfassen, wodurch eine iterative und arbeitsteilige Entwicklung erschwert wird und Fehler in Modellen unerkannt bleiben können. Entsprechend aufwendig ist es die Modelle stets auf dem aktuellen Stand und synchron zu einander zu halten.
Erschwerend kommt die Ausdrucksfähigkeit der Modellierungssprachen hinzu, die ein und dieselbe Aussage auf verschiedene Arten darstellbar macht. Dieses Problem kann mithilfe von Modellierungsrichtlinien einzugrenzen werden [20]. Für die bereits angesprochene interlinguale Konsistenzerhaltung ist der unterschiedliche Grad der Formalisierung und Ausdruckstärke jedoch weiterhin problematisch. So ist oft keine eindeutige Abbildung zwischen Modellelementen in einer Sprache auf einer abstrakteren Ebene auf Modellelementen in einer anderen konkreteren Ebene möglich und der Modellierer muss selbst entscheiden, wie die Abbildung vorgenommen werden soll. — Diese Problematik wird in [14] Abschnitt 7.4 sehr anschaulich am Problem der Abbildung von Architekturmodellen in Form von FMC-Aufbaudiagrammen auf UML-Klassendiagramme zur Beschreibung der konkreten Implementierung dargestellt. — Prinzipiell sind Strukturelle und Verhaltensbeschreibungen komplex in ihrer Konsistenzerhaltung, da hier Probleme teils recht subtil sein können und erst auf der Ebene der Implementierung ihr Auswirkungen zeigen. Beispiele für diese Problematik bezogen auf die UML werden im folgenden Abschnitt genauer betrachtet.
2.2 Typische Fehler in UML-Diagrammen
In Tabelle 1 ist eine Möglichkeit zur Klassifizierung von Inkonsistenzen dargestellt, die entwickelt wurde [4], um darauf aufbauend Inkonsistenzregeln zu erstellen. Bei dieser Klassifizierung wurden jedoch nur Klassen-, Zustands- und Sequenzdiagramme mit einbezogen. Aus akademischer Sicht scheinen diese Diagrammtypen am wesentlichsten zu sein, da es auch die sind, die von den meisten Ansätzen für die Werkzeugunterstützung betrachtet werden. Aus der Sicht der Anwender ist dies nicht so [16]. Hier spielen zwar Klassendiagramme die größte Rolle, Zustands- und Sequenzdiagramme werden jedoch deutlich seltener eingesetzt.
Die Klassifizierung unterscheidet einerseits die Ebenen, zwischen denen Konflikte auftreten können und andererseits den Aspekt, also Verhalten oder Struktur. Auf Modell-zu-Modell-Ebene können keine Verhaltenskonflikte auftreten, wenn man jedoch das Verhalten von einem Modell und darin definierten Modellelementen untersucht kann es inkompatible Definition geben, wie sie in Abb. 2 dargestellt sind.
| Konfliktebene | Verhalten | Struktur |
|---|---|---|
| Modell-Modell |
| |
| Modell-Instanz |
|
|
| Instanz-Instanz |
|
|
Das Beispiel zeigt insgesamt drei Probleme. So widersprechen die im Sequenzdiagramm definierten Nachrichten, sowohl der vorgebenden Navigationsrichtung, als auch der Kardialität der Assoziation, die im Klassendiagramm angegeben sind. Darüber hinaus ist Lecturer als abstrakt gekennzeichnet, wohingegen im Sequenzdiagramm konkrete Instanzen dieser Klasse dargestellt werden. Hier müsste bei der Implementierung also der Verantwortliche entscheiden, welcher Spezifikation er den Vorrang gibt. Da dies jedoch prinzipiell zu einer falschen bzw. ungewollten Umsetzung führen kann, hätten diese Inkonsistenzen im Vorfeld erkannt und behoben werden müssen.
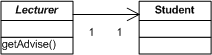
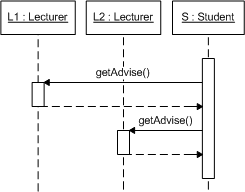 Abb. 2 Beispiel für inkompatible Definitionen zwischen Klassen- und Sequenzdiagrammen
Abb. 2 Beispiel für inkompatible Definitionen zwischen Klassen- und SequenzdiagrammenDie Verhaltenskonflikte auf Instanzebene können noch vielfältiger sein. Eine Aufrufinkonsistenz tritt beispielsweise immer dann auf, wenn ein Objekt einer Subklasse nicht verwendet werden kann, da es sich bei einer bestimmten Abfolge von Aufrufen nicht so verhält, wie es die vererbende Klasse spezifiziert. Bei der Verhaltensinkonsistenz wird die entgegengesetzte Richtung betrachtet und untersucht ob Subklassen dasselbe beobachtbare Verhalten zeigen wie ihre Elternklassen. In Abb. 3 ist ein Beispiel für die Definition von inkompatiblem Verhalten gegeben. So lässt das Zustandsdiagramm nicht die im Sequenzdiagramm angegebene Abfolge zu, da nach der answer-Nachricht stets eine answered-Nachricht erwartet wird, bevor eine neue answer-Nachricht empfangen werden kann.
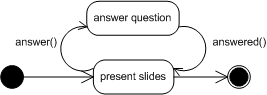
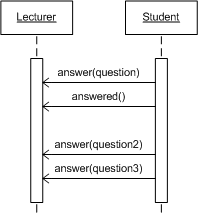 Abb. 3 Beispiel für Verhaltensinkonsistenzen zwischen Zustands- und Sequenzdiagrammen
Abb. 3 Beispiel für Verhaltensinkonsistenzen zwischen Zustands- und SequenzdiagrammenBei der Betrachtung von Strukturkonflikten gibt es auf der Modell-zu-Modell-Ebene das Problem von nicht erfüllbaren Assoziationen. Ein Beispiel für dieses Problem zeigt Abb. 4. Durch z.B. Zyklen in Assoziationen kann eine Situation entstehen, in der das Modell nicht instanziierbar ist, da die Assoziationen nur durch eine unendliche oder leere Menge an Objekten erfüllt werden können. Zu solchen Problemen kann es immer dann kommen, wenn z.B. eine bestehende Assoziation übersehen wird und eine Neue in ein Diagramm eingefügt wird. Bei einigen Modellen werden Elemente redundant verwendet und wenn bei den verschiedenen Vorkommen unterschiedliche Assoziationen auftreten, ist dies im Normalfall nur schlecht erkennbar.
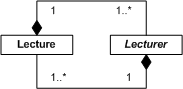 Abb. 4 Beispiel für unerfüllbare Assoziationen in einem Klassendiagramm
Abb. 4 Beispiel für unerfüllbare Assoziationen in einem KlassendiagrammDas Problem der unspezifizierten Referenzen (Dangling References) tritt immer dann auf, wenn im Laufe der Entwicklung in einem Diagramm ein bestimmter Typ z.B. für ein Attribut verwendet, seine Klassendefinition aber später wieder entfernt wurde und die Referenz nun nicht mehr spezifiziert ist bzw. „hängt“. Das gleiche Problem kann auch auf Modell-zu-Instanz-Ebene auftreten, wenn die Klasse eines Objekts noch nicht definiert oder bereits wieder entfernt wurde.
Auf der Instanzebene können unzusammenhängende Modelle zu Problemen führen. In Abb. 5 ist dies an einem Zustandsdiagramm veranschaulicht. Hier wurde der Answer-Question-Zustand entfernt, sodass der Use-Whiteboard-Zustand, nicht mehr erreicht werden kann. Dies ist an sich nicht problematisch, aber kann Quelle für zahlreiche Fehler sein. Bei der arbeitsteiligen Entwicklung wird dieser Zustand möglicherweise als Ausgangspunkt für die Modellierung von weiterem Verhalten genutzt, welches jedoch nie verwendet wird. Die Problemursache ist in einem komplexen Diagramm nicht immer offensichtlich und ihre Ermittlung bedarf im schlechtesten Fall eines entsprechend großen Aufwands. Ähnlich problematisch sind unzusammenhängende Klassendiagramme, in welchen einzelne Klassen nicht mehr verwendet werden, aber nicht entfernt wurden. Hier besteht das Risiko, dass alte Fehler wieder ins System eingebracht werden. Wenn beispielsweise die Funktionalität der noch vorhandenen aber nicht mehr verwendeten Klassen in andere Klassen integriert worden ist, können dort in der Zwischenzeit bereits Fehler behoben worden sein. Verwendet nun ein Entwickler statt der aktuellen Klassen die veralteten, gelangen eigentlich behobene Fehler wieder ins System. Daher sollte stets darauf geachtet werden, dass alle Modellelemente erreichbar sind und nicht mehr benötigte Elemente entfernt oder als veraltet gekennzeichnet werden.
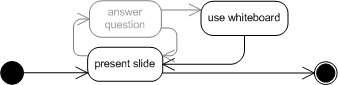 Abb. 5 Beispiel für das Problem unzusammenhängender Modelle
Abb. 5 Beispiel für das Problem unzusammenhängender Modelleanhand eines Zustandsdiagramms
Die hier dargestellten Fehler sind natürlich nur eine Auswahl und sollen nur eine Idee für die potenziell auftretenden Probleme geben. Weitere Beispiele und eine genauere Analyse der dargestellten Inkonsistenzklassen sind bei J. P. S. Wagemann [4] zu finden. Im folgenden Abschnitt soll ein Ansatz vorgestellt werden mit dem sich Inkonsistenzbehandlung in den Softwareentwicklungsprozess integriert und unter anderem die eben vorgestellten Probleme überwachbar und verfolgbar werden.
2.3 Inkonsistenzmanagement
Wie in den vorherigen Abschnitten ausgeführt, können diverse Aktionen im Entwicklungsprozess zu Inkonsistenzen führen. Unter anderem ist Unterspezifikation und das damit verbundene Treffen von Designentscheidungen eine wesentliche Ursache. Um diese und die anderen angeführten Probleme zu erkennen, sind die Konsistenzregeln ein zentraler Ausgangspunkt. Mit ihrer Hilfe werden mit dem von B. Nuseibeh [3] vorgeschlagenen Verfahren die verschiedenen entstehenden Modelle überwacht und auf Inkonsistenzen geprüft. Abbildung 2 zeigt diesen Kreislauf, der mit der Anwendung der Konsistenzregeln beginnt.
Sobald nun eine Inkonsistenz entdeckt wurde, muss diese in einem ersten Schritt genauer untersucht werden. Die betroffenen Modellelemente, die gegen die angewendete Regel verstoßen, müssen aufgefunden werden, um anschließend den Grund im Zusammenhang mit der verletzten Regel bestimmen zu können. Darauf aufbauend soll diese Inkonsistenz klassifiziert werden. Dies ist in verschiedenen geeigneten Dimensionen möglich. Vorgeschlagen werden unter anderem eine Einordnung anhand des Typs der verletzten Regel, der Typ der Aktion die zu dieser Inkonsistenz führte und die Auswirkung, welche diese Inkonsistenz auf das Modell hat.
Mithilfe dieser Einordnung lässt sich eine Metrik für das Bewerten von Modellen und Inkonsistenzen erstellen, um dem Entwickler ein objektives Kriterium zu geben, anhand dessen z.B. Entscheidungen zur Priorisierung von Inkonsistenzen und ihrer Behebung getroffen werden können. So können außerdem die Auswirkungen von Änderungen an einem Modell abgeschätzt oder auch verschiedene Entwürfe mit einer einheitlichen Metrik bewertet werden, um dieses Maß als Grundlage für eine Entscheidung für einen dieser Entwürfe zu verwenden.
![Ein Framework für Inkonsistenzverwaltung [3]](Inkonsistenz-Management.png) Abb. 6 Ein Framework für Inkonsistenzverwaltung [3]
Abb. 6 Ein Framework für Inkonsistenzverwaltung [3]Nachdem die Inkonsistenz erfolgreich eingeordnet bzw. charakterisiert wurde, kann sie ignoriert, toleriert oder behoben werden. Die Entscheidung für den Einzelfall wird auf der Basis der Einordnung aber auch mithilfe der Untersuchung von Auswirkung und Risiko der Inkonsistenz für die weitere Entwicklung getroffen. So kann es sinnvoll sein eine Inkonsistenz nicht zu beheben, da der Aufwand für eine solche Behebung fundamentale Auswirkungen auf das Modell hätte, diese Inkonsistenz aber aktuell kein Risiko für die weitere Entwicklung darstellt.
Ein Beispiel ist hierfür eine textuelle Spezifikation, die mit UML-Diagrammen angereichert ist. Die Diagramme widersprechen jedoch in einigen Punkten den Angaben im Text und eine Korrektur würde eine Überarbeitung aller Diagramme erfordern. Diese Behebung kann eventuell wirtschaftlich nicht sinnvoll sein und wird stattdessen toleriert. Dies kann bedeuten, dass die Diagramme schrittweise verbessert werden. Sie werden also nicht komplett sondern nur teilweise geändert, soweit, bis ausreichend viele Probleme behoben worden sind, um das Risiko und die Auswirkungen auf die weitere Entwicklung zu minimieren. Eventuell kann das Problem aber auch umgangen werden, in dem z.B. die textuelle Spezifikation als definitiv vermerkt wird und die UML-Diagramme nur als lose Beschreibung des Sachverhalts verwendet werden. Die Diagramme können trotzdem immer noch sehr nützlich sein, da sie es dem Menschen ermöglich die Konzepte und groben Zusammenhänge zu erfassen, auch wenn die Diagramme nicht komplett fehlerfrei sind. Sollte es das Problem zulassen, kann es auch erstmal verschoben und zu einem späteren Zeitpunkt in der Entwicklung behoben werden.
Ein unkritisches aber aufwendig zu behebendes Problem kann eventuell auch erst einmal ignoriert werden. Ein Beispiel für ein solches Problem wären Inkonsistenzen, die durch die arbeitsteilige Entwicklung von Klassen- und Verhaltensbeschreibungen entstehen können. An dem Punkt, an dem die Inkonsistenz geprüft wird, sind die Modelle unter Umständen so inkompatibel, dass zu diesem Zeitpunkt das Erreichen von Konsistenz zu aufwändig wäre. Hier ist in der weiteren Entwicklung eventuell ein besserer Zeitpunkt gegeben, an dem sich die Modelle bereits weiter angenähert haben, um dann die Konsistenz herzustellen.
Die Möglichkeit Inkonsistenzen zu ignorieren ist ein weiterer Grund für die Wichtigkeit der zyklischen Anwendung dieser Inkonsistenzprüfung und die immer wiederkehrende Bewertung, um im späteren Verlauf die Entscheidungen zur Inkonsistenzbehandlung neu treffen zu können und die Auswirkungen und Risiken auf Grundlage der aktuellen Situation neu zu bestimmen. Inkonsistenzen sollten daher nicht anders behandelt werden, als Fehler in der Software selbst und es sollten entsprechende Tools verwendet werden, um Fehler zu verfolgen, wie es z.B. mit Bug-Tracking-Tools gemacht wird.
Ebenfalls wichtig ist die Entscheidung, wann genau die Inkonsistenzprüfung im Entwicklungsprozess vorgenommen wird und in welchem Ausmaß wann und welche Regeln geprüft werden. Dies kann jedoch von Projekt zu Projekt unterschiedlich sein. So ist es eventuell sinnvoll eine schrittweise Prüfung von Regeln auf den verschiedenen Ebenen durchzuführen und so in einem Entwicklungsschritt nur die Regeln auf Projektebene zu prüft und erst in einem späteren Schritt das komplette Regelwerk anzuwenden. Hier sind immer die Vor- und Nachteile gegeneinander abzuwägen. Einerseits ist die Prüfung der Regeln mit einem bestimmten Aufwand verbunden, andererseits können Inkonsistenzen zu Qualitätsproblemen und damit noch höheren Kosten führen.
Zum Prüfen der Konsistenzregeln lassen sich unter anderem Model Reviews [15] wie sie auch für Quellcode verwendet werden durchführen. Dies ist natürlich aufwändig und mit verschiedenen Nachteilen verbunden. Einerseits ist diese Form nicht gut für große Mengen von Regeln geeignet die abgearbeitet werden müssen. Andererseits neigen die Personen dazu, die die Inkonsistenzen verantworten müssen, diese zu verharmlosen oder zu verteidigen, da sie sich persönlich angegriffen fühlen. Aber es kann natürlich auch Ausnahmefälle für Konsistenzregeln oder Fehler im Regelwerk geben, sodass die Regeln überarbeitet oder eingeschränkt werden müssen.
3 Ansätze für UML-Werkzeugunterstützung
Ein manuelles Prüfen der Konsistenzregel ist besonders bei großen Modellen wenig praktikabel und fehleranfällig. Daher sollte diese Prüfung, soweit möglich, mithilfe von Werkzeugen durchgeführt werden. Von den vielen möglichen Modellierungssprachen soll hier jedoch nur auf die UML eingegangen werden, da sie inzwischen den Status des Industriestandards genießt und ihre Eigenheiten hinreichend genau untersucht sind. Im Bereich der UML-Werkzeuge gibt es für die Grundlegenden syntaktischen Prüfungen bereits gute Unterstützung. Für semantische Regeln oder gar Regeln auf Projektebene hingegen nicht. Daher sollen in diesem Abschnitt Ansätze zu solchen Werkzeugunterstützungen vorgestellt werden. Begonnen wird mit einer kurzen Darstellung von Ansätzen, die sich auf spezielle Probleme konzentrieren. Dran anschließend werden allgemeine, regelbasierte Ansätze vorgestellt.
3.1 Spezielle Ansätze zur Inkonsistenzerkennung
Grundsätzlich kann man zwei Herangehensweisen an das Problem der Inkonsistenzerkennung identifizieren. Einerseits die Fokussierung auf eine spezielle Klasse von Problemen und deren effiziente Erkennung. Andererseits gibt es die allgemeinen Ansätze, die eine Menge von Konsistenzregeln auf ein Modell anwenden und somit Inkonsistenzen erkennen können.
Die speziellen Ansätze implizieren immer die Konsistenzregeln, um das behandelte Problem anzusprechen. Problematisch ist dabei, dass die Konsistenzregeln meist algorithmisch ausgedrückt werden und somit nicht ohne weiteres zwischen verschiedenen Werkzeugen ausgetauscht werden können. Zusätzlich sind sie meist nicht in einer Form ausgedrückt, die sich mit anderen Konsistenzregeln beliebig kombinieren lässt, um z.B. die Richtigkeit zu überprüfen. Dies ist jedoch nötig, da diverse Konsistenzregeln Beziehungen und Abhängigkeiten zwischen einander aufbauen und eventuell inkompatibel zu einander sind. Sie haben jedoch im Allgemeinen den großen Vorteil, dass die verwendeten Algorithmen auf genau diese eine Problemstellung optimiert sind und somit einen entsprechenden Performancevorteil gegenüber regelbasierten Ansätzen haben. Ein anderer Aspekt den die speziellen Ansätze ebenfalls abdecken können ist die formale Beweisbarkeit.
W. L. Yeung stellt beispielsweise ein sehr formales Verfahren vor [6], mit dem Klassen- und Zustandsdiagramme formal erfasst und auf ihre Konsistenz geprüft werden können. Dazu werden B Abstract Machine Notation und Communicating Sequential Processes (CSP) als Darstellungsform verwendet. Die Klassendiagramme werden in einem ersten Schritt mit der formalen B-Methode in die Abstract Machine Notation übersetzt. Im zweiten Schritt wird von den Zustandsdiagrammen abstrahiert und eine Abfolge von Call Events gewonnen, die dann in die CSP-Notation überführt werden. Daraus gewinnt man eine Art ausführbares System, welches sich dazu eignet, auf formale Art und Weise die Konsistenz der Diagramme zu prüfen. Auch wenn dieser Ansatz in seiner Anwendbarkeit noch beschränkt ist, da unter anderem momentan nur Objekte von zwei unterschiedlichen Klassen unterstützt werden, veranschaulicht er doch, in welcher Art Konsistenzprüfung durchgeführt werden kann.
Ein weiterer spezieller Ansatz wird von A. Maraee und M. Balaban vorgestellt [5] und beschäftigt sich mit der Frage, ob ein Klassendiagramm mit seinen verschiedenen Bedingungen und Beziehungen instanziierbar ist. Hierbei geht es genauer gesagt um sogenannte Constrained Generalization Sets. Der Ansatz baut auf älteren Verfahren aus dem Datenbankbereich auf, mit denen die Eigenschaften von E/R-Diagrammen untersucht wurden. Letztendlich funktioniert der beschreiben Ansatz auch wieder so, dass ein Klassendiagramm in eine geeignete Darstellung überführt wird. In diesem speziellen Fall wird mithilfe von vom Diagramm abgeleiteten Ungleichungen über mathematische Verfahren die strenge Erfüllbarkeit der Assoziationen im Diagramm überprüft. Weiterhin geben die Autoren an, dass der dargestellte Ansatz besser als die bis dahin verwendeten Methoden ist, da er keinen exponentiellen Ressourcenbedarf hat.
Letztendlich sind diese speziellen Probleme jedoch immer nur ein geringer Teilaspekt der kompletten Modellkonsistenz und aus praktischer Sicht gibt es wie bereits angedeutet auch Bedarf an domänenspezifischen Konsistenzregeln, die durch solche Ansätze prinzipiell nur bedingt abdeckbar sind. Daher wird im folgenden Abschnitt auf die allgemeiner einsetzbaren regelbasierten Ansätze eingegangen.
3.2 Regelbasierte Ansätze zur Inkonsistenzerkennung
Wie bereits mit der Definition in Abschnitt 2 eingeführt, sind Konsistenzregeln das wesentlichste Mittel, um die Beziehungen zwischen Modellen und Modellelementen so zu beschreiben, dass über die Konsistenz geurteilt werden kann. Daher ist der erste Schritt, der bei einer Entwicklung einer Toolunterstützung gemacht wird, die Entwicklung einer geeigneten Darstellungsform für diese Regeln, abgestimmt auf die zu verwendende technische Infrastruktur für das Überprüfen dieser Regeln.
Da auf diesem Gebiet heut noch kein einheitlicher Standard etabliert ist, werden in der Forschung erst einmal die diversen Möglichkeiten untersucht und auf ihre Tauglichkeit getestet. So arbeitet P. Andre [7] mit einem Ansatz auf Basis von abstrakten Datentypen und dem Larch Prover [17]. Der Larch Prover wird dabei zur Auswertung der in Form von prädikatenlogischen Aussagen formulierten Konsistenzregeln verwendet. Ähnlich wird von J. P. S. Wagemann [4] sowie J. Simmonds und M. C. Bastarrica [10] eine Untermenge der Prädikatenlogik verwendet. Als technische Grundlage dient hier mit Loom [18], ein System, dass Mustererkennung beherrscht. Mit Beschreibungslogik werden die Konsistenzregeln aufgestellt, die anschließend auf das zu prüfende, in die Loom-Wissenbasis überführte, Modell angewendet werden.
Von D. Chiorean [8] und B. Hnatkowska [9] wird hingegen die von der OMG im Zusammenhang mit UML entworfene OCL verwendet, um Konsistenzregeln aufzustellen. Ein Beispiel für solch eine Regel, genauer gesagt eine Wellformedness-Regel, zeigte bereits Abb. 1. Hier werden jedoch über die Wellformedness hinausgehende Regel aufgestellt und anschließend mithilfe eines OCL-Tools ausgewertet.
Da UML-Modelle im Allgemeinen als Graphen mit besonderen Eigenschaften aufgefasst werden können, liegt es nahe, dass sich auch auf der Ebene dieser Darstellungsform Ansätze entwickelt haben. Zwei dieser Ansätze wurden von R. Wagner [11] und T. Mens [12] entwickelt. An dieser Stelle soll zu Veranschaulichung der dahinterstehenden Ideen näher auf den Ansatz von T. Mens [12] eingegangen werden.
Grundsätzlich gilt, dass das vorliegende UML-Modell, bevor es verarbeitet bzw. geprüft werden kann in einer geeigneten Darstellung vorliegen muss. In diesem Fall handelt es sich bei dieser Darstellung um einen sogenannten getypten Graphen. Aufbauend auf ein vereinfachtes UML-Metamodell wird das UML-Modell entsprechend mit Knoten von einem bestimmten Typ und Kanten, die Multiplizitäten tragen können, dargestellt. Diese Darstellungsform ist wie bei den anderen erwähnten Ansätzen ebenfalls wieder auf ein Tool zur Verarbeitung optimiert. In diesem Fall handelt es sich mit AGG [19] um ein Werkzeug zur Verwendung von Graph-Grammatiken und Graph-Transformationen.
Daher sind die Konsistenzregeln in diesem Fall in Form von sogenannten Graph-Transformationsregeln angegeben. In Abb. 7 ist eine Regel für die Erkennung von unspezifizierten Referenzen dargestellt. Die Regeln bestehen dabei immer aus drei Teilen. Das erste Teil, die sogenannte Left-Hand Side stellt das Muster dar, das im Graphen gefunden werden soll, um die Regel anwenden zu können. Die Negative Application Condition gibt darüber hinaus noch die Möglichkeit, die Anwendung der Regel weiter einzuschränken. Prinzipiell wird immer auf das Vorhandensein oder Fehler bestimmter Strukturen geprüft.
In diesem Fall wird also ein Operationsknoten gesucht, der einen Parameterknoten über eine hasParam-Kante hat, aber der Parameterknoten darf in diesem Fall nicht über eine type-Kante mit einem Klassenknoten verbunden sein. Damit werden letztendlich alle Parameter gefunden, die bisher noch nicht mit einem Typ versehen wurden. Wenn die Regel angewendet werden kann, kommt die Right-Hand Side der Regel zum Zuge. Diese sagt aus, wie der Graph verändert werden soll. In der angegebenen Regel wird ein Konfliktknoten eingefügt, um den Benutzer über das Problem zu informieren.
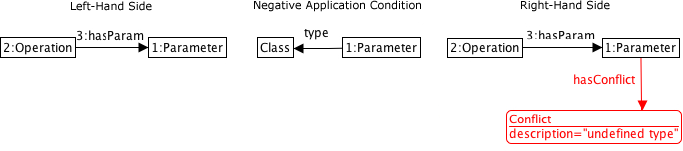 Abb. 7 Graph-Transformationsregel für die Erkennung
Abb. 7 Graph-Transformationsregel für die Erkennunguntypisierter Operationsparameter, nach [12]
Abbildung 8 zeigt einen solchen Graphen mit bereits angewendeten Regeln. Auf der linken Seite, unter dem Klassenknoten mit dem Namen A ist eine Operation mit einem Parameter zu sehen, der der vorgestellten Regel entspricht. Der eingefügte Konfliktknoten kann nun z.B. vom Tool ausgewertet werden und den Nutzer über die Inkonsistenz informieren und unter Umständen Verbesserungen vorschlagen.
Wie bereits früher angemerkt, kann es zwischen den Konsistenzregeln Abhängigkeiten geben und besonders auf der Ebene des getypten Graphen kann dies zu Problemen führen. So führt das Anwenden der Transformationen eventuell zu Änderungen, die andere Regeln beeinflussen. Dies kann insbesondere bei einer weitergehenden Werkzeugunterstützung mit automatisierter Fehlerbehebung zu Problemen führen. T. Mens geht auf diese Probleme noch genauer ein [12], daher soll es an dieser Stelle bei einer kurzen Darstellung des grundlegenden Ansatzes bleiben.
![Darstellung eines Klassendiagramms als typisierter Graph mit eingefügten Konfliktknoten für Konsistenzprobleme [12]](TypeGraph-mit-Defekten.png) Abb. 8 Darstellung eines Klassendiagramms als typisierter Graph mit eingefügten Konfliktknoten für Konsistenzprobleme [12]
Abb. 8 Darstellung eines Klassendiagramms als typisierter Graph mit eingefügten Konfliktknoten für Konsistenzprobleme [12]Abschließend sei noch auf die von T. Mens hervorgehobene breite Anwendbarkeit des Verfahrens hingewiesen. So sieht er die Möglichkeit, mit entsprechenden als Graph-Transformationsregeln definierten Konsistenzregeln, Standardverletzungen zu erkennen. Hierbei sind sowohl industrie- als auch unternehmensinterne Standards gemeint. Das Prüfen von Modellierungsrichtlinien und Namenskonventionen ist ebenfalls möglich. Die Untersuchung auf Verletzungen in Syntax oder Semantik (Well-formedness) ist ja der Ausgangswunsch, aber darüber hinaus soll die Erkennung von unvollständigen Modellen, Redundanz, schlechte Praktiken und Anti-Patterns ebenfalls gelingen. Mit einer Hilfe in Form von Hinweisen auf Refactoring-Möglichkeiten und visuellen Problemen soll das Ganze für den Nutzer außerdem noch weit über die Inkonsistenzerkennung hinausgehen und somit die praktische Arbeit mit Modellen deutlich erleichtern.
Allerdings scheint dies bisher noch Zukunftsmusik zu sein, da der vorgestellte Prototyp nicht in eines der Standard UML-Werkzeuge integriert wurde, sondern soweit ersichtlich nur eine akademische Machbarkeitsstudie darstellt.
4 Zusammenfassung und Fazit
Abschließend lässt sich sagen, dass Inkonsistenz ein ständiges Problem im Softwareentwicklungsprozess darstellt, aber nicht nur als Mangel sondern auch als Hilfsmittel betrachtet werden sollte. Die Fehler, die zu Inkonsistenzen führen, zeigen meist Probleme auf, welche im unterschiedlichen Verständnis der Problemdomäne der Beteiligten begründet sind und bieten damit einen guten Ansatzpunkt um das Team insgesamt besser abzustimmen und eventuelle Kommunikationsdefizite zu beseitigen. Der vorgeschlagene Ansatz zum Umgang mit Inkonsistenzen ist im Eigentlichen nur eine Abstrahierung von typischen Bug-Tracking-Verfahren auf Quellcodeebene. Mit einer zusätzlichen Anwendung auf Modelle lässt sich relativ gut sicherstellen, dass der gewünschte Grad an Konsistenz in den erstellten Modellen erricht und somit die Qualität des Endprodukts gesichert werden kann.
Die vorgestellten Konsistenzprobleme und Ansätze, welche sich vorwiegend mit den Klassen-, Sequenz- und Zustandsdiagrammen der UML befassen, zeigen auf, wo der Bedarf ist und wie eine werkzeuggestützte Konsistenzsicherung aussehen könnte. Jedoch muss leider festgestellt werden, dass diese Ansätze bisher noch nicht in industriellen Produkten Verwendung finden und die betrachteten Modelle teilweise nicht die Relevanz in der Praxis haben, wie eventuell vermutet wird.
Grundsätzlich scheinen die regelbasierten Ansätze eine große Flexibilität zu besitzen und somit die technische Grundlage für eine vielfältige Unterstützung bei der Qualitätssicherung für Modelle bieten zu können. Daher bleibt zu hoffen, dass aus den recht vielversprechenden Prototypen richtige Produkte für die modellgestützte Entwicklung entstehen. Diese könnten dem Wunsch nach einer hochintegrierten Werkzeuglösung gerecht werden und die Qualität von Software somit positiv beeinflussen.
Quellenverzeichnis
- 1. B. Nuseibeh, To Be and Not to Be: On Managing Inconsistency in Software Development, IEEE Computer Society, 1996
- 2. E. Holz, UML Vertieft, Vorlesungsunterlagen HPI, Potsdam, Juli 2006 (auf Basis des UML2.0 Standards)
- 3. B. Nuseibeh et al., Leveraging Inconsistency in Software Development, Computer, IEEE Computer Society, 2000
- 4. J. P. S. Wagemann, Consistency Maintenance of UML Models with Description Logics, Vrije Universiteit Brussel, 2003
- 5. A. Maraee & M. Balaban, Efficient Decision of Consistency in UML Diagrams with Constrained Generalization Sets, Workshop Materials of the 1st Workshop on Quality in Modeling, 2006
- 6. W. L. Yeung, Checking Consistency between UML Class and State Models Based on CSP and B, Journal of Universal Computer Science, 2004
- 7. P. Andre et al., Checking the consistency of UML class diagrams using Larch Prover 2000
- 8. D. Chiorean et al., Ensuring UML Models Consistency Using the OCL Environment. Electr. Notes Theor. Comput. Sci., 2004
- 9. B. Hnatkowska, Consistency Checking in UML Models, 2001
- 10. J. Simmonds & M. C. Bastarrica, Description Logics for Consistency Checking of Architectural Features in UML 2.0 Models, Universidad de Chile, 2004
- 11. R. Wagner, A Plug-In for Flexible and Incremental Consistency Management University of Paderborn, 2003
- 12. T. Mens et al, Graph-Based Tool Support to Improve Model Quality, Workshop Materials of the 1st Workshop on Quality in Modeling, 2006
- 13. B. Nuseibeh, Computer-Aided Inconsistency Management in Software Development Imperial College, London, 1995
- 14. A. Knöpfel, B. Gröne, P. Tabeling, Fundamental Modeling Concepts: Effective Communication of IT Systems, John Wiley & Sons, 2006
- 15. S. W. Ambler, Model Reviews: Best Practice or Process Smell? Ambysoft Inc., 2007
http://www.agilemodeling.com/essays/modelReviews.htm - 16. B. Dobing & J. Parsons, How UML is used, Commun. ACM, vol. 49, ACM Press, 2006
- 17. S. J. Garland & J. V. Guttag, LP, the Larch Prover, MIT Computer Science and Artificial Intelligence Laboratory, 2000, http://www.sds.lcs.mit.edu/spd/larch/LP/overview.html
- 18. Loom, University of Southern California, 2007,
http://www.isi.edu/isd/LOOM/LOOM-HOME.html - 19. G. Taentzer et. al., The Attributed Graph Grammar System, TU Berlin, 2006,
http://tfs.cs.tu-berlin.de/agg/ - 20. A. Meyer, Modellierungsrichtlinien und Qualität in der modellbasierten Softwareentwicklung, Hasso-Plattner-Institut, 2007
- 21. OMG, Unified Modeling Language: Superstructure, Version 2.1.1, 2007, Seite 80, http://www.omg.org/cgi-bin/apps/doc?formal/07-02-05.pdf