 I am working at the
I am working at the RESTful Web Services
Stefan Marr
Seminar Advanced Database Technology 2005/2006
Hasso-Plattner-Institut für Softwaresystemtechnik
stefan.marr at hpi.uni-potsdam.de
Abstract
Der REST-Architekturstil und der Representational State Transfer als Basis für das Design von Web Services werden vorgestellt. Als Heranführung werden die Grundlagen für interoperable Schnittstellen behandelt, welche an HTTP als eine Implementierung konkretisiert werden, um darauf aufbauend die vier wesentlichen Fragen und acht notwendigen Prinzipien zur konkreten Erstellung eines RESTful Web Services an einem Beispiel zu verdeutlichen. Darüber hinaus werden kurz Ansätze zur Lösung gängiger Probleme angerissen, um anschließend auf Vorteil des REST-Architekturstils insgesamt einzugehen und damit ein Fazit zu ziehen.
Keywords: Interoperabilität, REST, Systemarchitektur, Web Services
1. Einleitung
Der Wunsch nach Interoperabilität zwischen verschiedenen Systemen hat in den letzten Jahren zur verstärkten Entwicklung sogenannter Web Services geführt. Wobei hier in der überwiegenden Mehrzahl Software entwickelt wurde, welche auf XML-Techologien aufsetzt und SOAP als Nachrichtenprotokoll einsetzt, um mit verschiedensten Systemen Daten auf einfache Art und Weise austauschen zu können.
Mit der Zeit zeigt sich jedoch immer mehr, dass auch mit diesem technologischen Ansatz nicht alle Probleme gelöst werden können, sich weitere, neue Probleme ergeben und die Komplexität der Gesamtsysteme insgesamt steigt, ohne jedoch das eigentliche Ziel, echte Interoperabilität, zu erreichen.
In seiner Doktorarbeit [1] aus dem Jahr 2000 formulierte R. T. Fielding einen Architekturstil für verteilte Hypermedia-Systeme, genannt Representational State Transfer (REST), welcher anschließend von verschiedenen anderen aufgegriffen worden ist und seit dem als Ansatz für interoperablere Web Services propagiert wird.
Dieser Ansatz soll nun an dieser Stelle vorgestellt und anhand eines Beispiels für den praktischen Einsatz aufbereitet werden. Im Anschluss daran werden noch einige weitere Aspekte sowie Vor- und Nachteile gegenüber einer auf SOAP aufsetzenden Architektur angerissen.
2. Der REST-Architekturstil
2.1. Representational State Transfer
Wie bereits erwähnt, wurde der Begriff in [1] von R. T. Fielding geprägt. Ein Hauptaugenmerk wird bei diesem Architekturstil auf Resourcen gelegt. Diese können in einer oder mehreren Repräsentationen verfügbar sein und werden über URIs (Uniform Resource Identifiers) identifiziert. Dabei wird Ressource selbst als eine semantische Entität definiert, von der ihr Autor wünscht, identifizierbar zu sein, ohne einen speziellen Wert zu implizieren. Der Inhalt bzw. die Repräsentationen einer Ressource können sich so ändern, ohne dass der Identifikator, der URI, sich ebenfalls ändern muss.
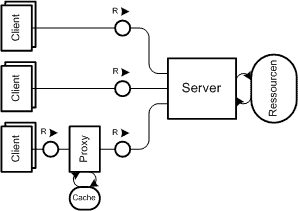 Abb. 1. Einfache Client-Server Architektur, wie im Web üblich mit verschiedenen Clients und optional dazwischen geschaltetem Proxy-Server
Abb. 1. Einfache Client-Server Architektur, wie im Web üblich mit verschiedenen Clients und optional dazwischen geschaltetem Proxy-ServerWeiterhin handelt es sich grundsätzlich um eine Client-Server Architektur, wie sie für das Web üblich ist. Ein einfaches Beispiel ist in Abb. 1 dargestellt. Ein Server wird üblicherweise von vielen Clients genutzt, welche prinzipiell grundverschieden sein können. Darüber hinaus kann es verschiedene Zwischenknoten geben. In diesem Beispiel ist einmal nur ein einfacher Proxy-Server dargestellt. Die Architektur könnte jedoch durch weitere Knoten ergänzt werden, seien es nun Systeme für Load-Balancing und Datenhaltung oder auch Zwischenknoten zum Anschluss von anderen komplexen Systemen.
Der nächste wichtige Punkt in der REST-Architektur ist die Zustandslosigkeit der Server. Dies bedeutet, dass der Client bei einer Anfrage alle relevanten Daten zum Verarbeiten dieser Anfrage explizit mitschicken muss. Idealerweise soll der komplette Session-Kontext beim Client liegen. Dies hat verschiedene Vorteile, unteranderem Skalierbarkeit, da der Server keine Daten verwalten muss, die über eine Anfrage hinausgehen.
Daraus folgt auch die Vorstellung, dass ein Client durch die Repräsentation einer Ressource in einen Zustand versetzt wird und Hyperlinks als Transitionen zwischen Zuständen angesehen werden können. Somit kann die Traversierung einer durch Hyperlinks verbundenen Struktur als Ablauf in einem Automatengraphen interpretiert werden.
Um die Effizienz so einer Architektur zu steigern, werden Caches z.B. mittels Proxy-Servern verwendet. Dies setzt jedoch voraus, dass ein Server eine Antwort zu einer Anfrage so markiert, dass ein Cache entscheiden kann, ob er die Antwort zwischenspeichern darf oder nicht.
Ganz besonderer Wert wird in diesem Architekturstil auf die Schnittstellen zwischen Systemen gelegt. Diese sollen möglichst uniform und minimal sein, damit die Komplexität des Gesamtsystems nicht unnötig erhöht wird. Dazu nun mehr im folgenden Abschnitt.
2.2. Interoperable Schnittstellen
Die Verwendung von speziellen Technologien allein bringt einem System noch keine Interoperabilität mit anderen Systemen, dazu gehört außerdem eine geeignete Architektur und auf Verteilung spezialisierte Schnittstellen. Dies ist auch einer der größten Kritikpunkte am SOAP-Ansatz, vonseiten der REST-Vertreter. SOAP [3] und die WSDL [4] selbst geben keinerlei Standards oder Anregungen vor, wie Schnittstellen gestaltet werden sollten, um möglichst interoperabel zu sein.
Allgemein gilt für Schnittstellen, die nicht prozesslokal genutzt werden sollen, dass sie möglichst grobgranular zu gestaltet sind. Dazu im Gegensatz sollen prozesslokal verwendete Schnittstellen möglichst feingranular untergliedert sein und aus den Prinzipien der objektorientierten Programmierung den bestmöglichen Nutzen ziehen.
Remote-Interfaces, also nicht prozesslokal genutzte Schnittstellen, sollten hingegen möglichst dienstorientiert entworfen werden. Dies bedeutet, dass sie nur Werte – im Sinne eines Data Transfer Objects – verwenden sollen, nicht jedoch direkte Objekt-Referenzen, und seiteneffektfrei sind. Damit ermöglichen sie eine lose Kopplung und sind somit ein wesentlicher Faktor für eine hohe Interoperabilität.
Ein weitere Punkt ist in diesem Zusammenhang die Performance von Remote-Interfaces. Diese wird durch grobgranulare Schnittstellen sehr begünstigt, da die Anzahl der verteilten Methodenaufrufe, gegenüber feingranularen Schnittstellen, deutlich reduziert werden kann.
Damit ist auch verbunden, dass die Aufrufparameter alle Informationen beinhalten müssen, die zum Abarbeiten der Anfrage notwendig sind. Über diese Architektur wird also die Komplexität der Schnittstelle reduziert und in eine tiefere Schicht verlagert, wodurch man die Einheitlichkeit der nach außen angebotenen Schnittstelle erreicht.
Dieser Gedanke wird in Verbindung mit dem REST-Architekturstil nun soweit entwickelt, dass man eine Schnittstelle aus ressourcengenerischen Methoden spezifiziert. Ressourcengenerische Methoden haben eine eindeutige Semantik unabhängig von einer speziellen Ressource, wodurch Annahmen zu ihrer Wirkungsweise getroffen werden können, ohne die Ressource kennen zu müssen, auf die sie angewendet werden. Die Möglichkeit auf Grundlage partiellen Wissens Informationen abzuleiten ist sehr positiv im Sinne der Interoperabilität, da es dadurch möglich wird Abläufe oder Zusammenhänge auch für unbekannte Systeme abzuschätzen und somit automatisierte Operationen auf deren Ressourcen vorzunehmen.
Die Anzahl solcher ressourcengenerischer Methoden muss prinzipiell nicht einmal beschränkt sein, jedoch zeigen unter anderem die Erfahrungen aus dem Datenbankbereich, dass für Operationen auf Daten vier universelle Methoden ausreichen, die sogenannten CRUD-Operationen (Create, Retrieve, Update, Delete). Da im REST-Architekturstil jedoch allgemeiner von Ressourcen die Rede ist, scheint eine exakte Einschränkung auf bestimmte Methoden erst einmal schwierig.
Mittels der Theorie der Speech Acts lässt sich zeigen, wie in [5,6] ausgeführt wird, dass die Anzahl der nötigen Methoden jedoch gering ist und sich so eine minimale sowie uniforme Schnittstelle spezifizieren lässt, mit der alle denkbaren Anwendungsfälle von Geschäftstransaktionen modellieren werden können.
Neben der Interoperabilität der Schnittstellen bekommt noch ein weiterer Punkt im REST-Architekturstil zentrale Bedeutung, die Adressierbarkeit der Ressourcen. Grundannahme hier ist, dass es ein eindeutiges System geben muss, in dem alle Ressourcen direkt identifiziert werden können sollen. Eine hierarchische Anordnung ist hierbei von Vorteil jedoch nicht Kern der Aussage. Ein sehr verbreitetes System zur direkten Adressierung stellt der URI-Namensraum bereit und mit dem in diesem Zusammenhang oft gebrauchten Hypertext Transfer Protocol (HTTP) gibt es außerdem einen sehr verbreiteten Standard, der sich dem REST-Architekturstil bedient, dazu mehr im folgenden Abschnitt.
2.3. Das HTTP-REST-Interface
Im HTTP sind acht verschiedene Methoden definiert um einfache Abfragen, oder auch komplexere Operationen auf einem kompatiblen Server durchzuführen. Unter diesen Operationen gibt es nun vier Spezielle, GET, POST, PUT und DELETE. Diese lassen sich zum einen eins zu eins auf die CRUD-Operationen abbilden (POST=Create, GET=Retrieve, PUT=Update, DELETE=Delete), und zum anderen sind sie wie in [6] gezeigt vollständig im Sinne der Modellierbarkeit von Geschäftstransaktionen.
Damit bilden diese vier HTTP-Methoden eine geeignete minimale und uniforme Auswahl und lassen sich als Implementierung des REST-Architekturstils verwenden.
Wie bereits erwähnt, muss für ein uniformes ressourcengenerisches Interface ein besonderes Augenmerk auf die Semantik und die Eigenschaften der Methoden gelegt werden. Im HTTP sind die Methoden wie folgt spezifiziert.
GET ist dafür gedacht, die Repräsentation einer Ressource abzufragen und soll nach [9] safe und idempotent sein. Safe bedeutet in diesem Zusammenhang, dass durch den Aufruf einer sicheren Methode an einer Ressource, keinerlei weiterreichende Wirkung hervorgerufen wird. Ein GET-Aufruf soll also keine weitere Bedeutung haben, als das Abfragen einer Ressource. Es soll z.B. nicht möglich sein, über einen GET-Aufruf Daten zu löschen, zu verändern oder gar einen Vertrag mit jemandem zu schließen. Unter idempotent versteht man, dass der Seiteneffekt für N > 0 identische Anfragen derselbe ist, wie der für eine einzelne Anfrage, abgesehen von Fehlern.
Mit POST wird in lose gekoppelter Art und Weise der Zustand auf einem Server verändert. Es werden mit dieser Methode z.B. bestehende Ressource um Kommentare ergänzt, ein Beitrag einer Gruppe von Artikeln hinzugefügt, eine Datenbank erweitert oder Daten aus einem Formular übermittelt.
PUT wird verwendet um bestehende Ressourcen an einem speziellen URI zu ändern, in dem ihr neuer Wert dort abgelegt wird oder um an einem bestimmten URI eine neue Ressource anzulegen. Grundsätzlich ist für das Erstellen einer neuen Ressource aus semantischen Gründen POST der PUT-Methode vorzuziehen, da in den wenigsten Fällen von vornherein klar ist, welchen exakten Identifikator eine neue Ressource bekommen wird, wenn diese z.B. in eine Datenbank eingefügt wird. PUT soll außerdem idempotent sein.
Mit DELETE wird der Server aufgefordert, eine Ressource zu löschen. Diese Methode soll ebenfalls idempotent sein.
3. Entwurf eines RESTful Web Services
3.1. Ein Bookmark Web Service
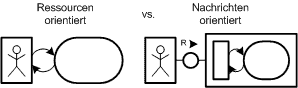 Abb. 2. Gegenüberstellung der ressourcenorientierten Sichtweise mit der nachrichten- bzw. RPC-orientierten Sichtweise auf ein System
Abb. 2. Gegenüberstellung der ressourcenorientierten Sichtweise mit der nachrichten- bzw. RPC-orientierten Sichtweise auf ein SystemUm die abstrakte Beschreibung des REST-Architekturstils mit Leben zu füllen, wird an dieser Stelle exemplarisch ein Web Service für die Verwaltung von Bookmarks entworfen. Dieser Service ist dazu gedacht einzelne Bookmarks aufzunehmen, welche über Tags also Schlüsselwörter gruppiert werden können. Zusätzlich soll es die Möglichkeit geben verschiedene Gruppen von Bookmarks abzufragen, etwa zu einem speziellen Schlüsselwort oder von einem bestimmten Nutzer. Dabei soll besonders auf den in Abb. 2 dargestellten Unterschied zwischen dem Entwurf eines ressourcenorientierten Systems geachtet werden. Ziel eines RESTful Web Services ist es Ressourcen über URIs verfügbar zu machen und nicht Services über eine nachrichtenorientierte Schnittstelle.
3.2. Vier Fragen und acht Prinzipien
Für den Entwurf eines RESTful Web Services müssen die folgenden vier Fragen beantwortet werden:
1) Welche Ressourcen gibt es?
2) Welche Repräsentationen sind sinnvoll?
3) Welche Methoden werden von den einzelnen Ressourcen unterstützt?
4) Welche Status-Codes bzw. Fehler können zurückgegeben werden?
Mit dem Beantworten dieser Fragen erhält man die notwenigen Informationen für eine anschließende Implementierung. Zusätzlich wurden in [12] acht Prinzipien identifiziert, an welche man sich halten sollte um effiziente und interoperable Web Services zu erhalten, die auch den semantischen Ansprüchen des REST-Architekturstils gerecht werden. Eine Übersicht über die Prinzipien ist in Abb. 3 zu finden. Im folgenden Abschnitt werden die Fragen durchgearbeitet und die Prinzipien allgemein erläutert, um sie dann jeweils auf den Bookmark Web Service anzuwenden.
| (1) | Auswählen der anzubietenden Ressourcen aus allen konzeptionellen Entitäten |
| (2) | Entwurf der Ressourcen zum schrittweisen Abfragen von weiteren Daten |
| (3) | Einen URI für jede Ressource und Vermeidung des RPC-Stils |
| (4) | Klassifizieren der Ressourcen nach den auf ihnen ausführbaren Methoden |
| (5) | Eine Ressourcenabfrage über GET sollten vollständig seiteneffektfrei sein und die Ressource nicht modifizieren |
| (6) | Verbindung von Ressourcen über Links in ihren Repräsentationen herstellen |
| (7) | Spezifizieren der Abfrageergebnisse mit einer Schemabeschreibung, für POST und PUT zusätzlich die Anfrageformate spezifizieren |
| (8) | Anfertigung einer Beschreibung zum Aufrufen des Services mit der WSDL oder einem einfachen Textdokument |
3.3. MyBookmarkWebService
1) Welche Ressourcen gibt es?
Als erster Schritt ist zu klären, welche Ressourcen für einen Service benötigt werden. Anschließend werden diese konzeptionellen Entitäten dahingehend untersuchen, ob es sinnvoll ist sie nach außen hin anzubieten, wie es Prinzip (1) vorsieht. Für einige Ressourcen ist dies z.B. entweder aus Sicherheitserwägungen oder Performanceaspekten heraus nicht sinnvoll.
Der nächste Schritt besteht nun darin, diese Ressourcen nach Prinzip (2) zu optimieren, also so zu strukturieren, detaillierte Informationen erst auf eine direkte Anfrage zurück gegeben werden. Dies ist sinnvoll um die zu übertragende Datenmenge zu beschränken und redundante Übertragungen zu vermeiden. Diese Untergliederung sollte jedoch nicht zu feingranular werde, sondern es sollte ein gutes Mittel zwischen minimaler Anzahl von Anfragen und minimaler Datenmenge pro Anfrage gefunden werden.
Um nun die Ressourcen identifizieren zu können, muss ein Namensraum von URIs entwickelt werden, wobei Prinzip (3) zu beachten ist. Das HTTP-REST-Interface besteht aus Interoperabilitätsüberlegungen aus den vier genannten Operationen und wie erwähnt, werden besonders an die GET-Operation zusätzlich Anforderungen gestellt, denn diese soll, sicher und idempotent sein.
Beim Entwerfen des Namensraums scheint es oft bequem zu sein, in Anlehnung an das unterliegende Objektmodell eine Art RPC-Stil zu verwenden und damit zusätzliche Semantik der GET-Operation hinzuzufügen, dies ist jedoch ausdrücklich zuvermeiden. Ob dies ein scheinbar ungefährliches http://.../getBookmark?id=4 oder ein offensichtlich problematischeres http://.../deleteBookmark?id=4 ist sei dabei erstmal nicht relevant. Als Regel gilt, zur Identifizierung von Ressourcen werden Nomen verwendet und keine Verben. Dass die zusätzliche Semantik große Probleme birgt, zeigt ein einfaches Beispiel. Unteranderem verlässt sich Google darauf, dass GET eine sichere Operation ist und parst so das Web. Sollte Google nun auf einen potenziell nicht abgesicherten Service treffen, der diese erweiterte GET-Semantik implementiert, ist es durch aus denkbar, wenn auch hoffentlich nicht realistisch, dass alle mühsam gesammelten Bookmarks mit einmal gelöscht werden. Daher sollte jegliche nicht [9] entsprechende Semantik vermieden werden.
Weiterhin gilt, dass Ressourcen selbst eindeutig ohne eine Query in dem URI identifiziert werden können sollen, da Query in [15] als die Zeichenkette definiert ist, welche hinter einem ?-Zeichen angegeben ist und Informationen beinhaltet, welche von der Ressource selbst interpretiert werden sollen und somit zur Ressourcenidentifikation nur die URI-Teile vor dem ?-Zeichen infrage kommen. Queries sollten immer dann verwendet werden, wenn die daraufhin erzeugten Ergebnisse nicht selbst als Ressource gewertet werden sollen.
Von Anfang an angewendet auf dieses Beispiel ergeben sich erst einmal die Ressourcen. Diese sind einzelne Bookmarks, Sammlungen von Bookmarks, einzelne Schlüsselworte, Listen von Schlüsselworten, sowie die Nutzerprofile als einzelne Ressourcen, welche z.B. Verweise auf die Sammlung von Bookmarks und verwendeten Schlüsselworte des einzelnen Users enthalten können. Bis auf die einzelnen Schlüsselworte als eigenständige Ressource müssen in diesem Fall alle Entitäten nach außen zur Verfügung gestellt werden, um den Service realisieren zu können.
URI-Namensraum
| URI | Art der Ressource | Beschreibung |
|---|---|---|
| {user}/bookmark/{id} | Bookmark | Ein einzelnes Bookmark für {user} |
| {user}/bookmarks/ | Bookmarksammlung | Die 20 neusten Bookmarks von {user} |
| {user}/bookmarks/tags/{tag}/ | Bookmarksammlung | Die 20 neusten Bookmarks von {user} mit dem Schlüsselwort {tag} |
| {user}/bookmarks/date/{year}/ | Bookmarksammlung | Alle Bookmarks von {user} aus dem Jahr |
| {user}/keywords/ | Keywordliste | Liste aller von {user} verwendeten Schlüsselworte |
| {user}/profile | Nutzerprofil | Profil von {user} |
| all/bookmarks/ | Bookmarksammlung | Die 20 neusten Bookmarks im System |
| all/keywords/ | Keyword-liste | Liste aller verwendeter Schlüsselworte |
Um Prinzip (2) zu genügen, muss überlegt werden, welche Daten schrittweise bezogen werden sollen. Bei der Gestaltung der Bookmarksammlungen ist abzuwägen, ob diese nur Verweise auf konkrete Bookmarks enthalten sollen oder die kompletten Bookmarks. Erstere Variante wäre aus Performancesicht nachteilig. Die deutlich erhöhte Anzahl von Anfragen zum Ermitteln der Bookmarks ist nicht über die potenzielle Einsparung der Übertragungsmenge zu rechtfertigen, da die Metadaten eines Bookmarks im Allgemeinen sehr gering sind. Ein Gegenbeispiel dazu könnte eine Bestellung sein, die sich aus den üblichen Daten wie Liefer- und Rechnungsadresse sowie der Liste der bestellten Produkte zusammensetzt. In der Repräsentation dieser Bestellung sollten keine Produktbeschreibungen hinterlegt sein, sondern diese sollten idealerweise durch verfeinernde Anfragen abgefragt werden, da sie selten direkt benötigt werden und die Datenmenge der Beschreibung deutlich größer ausfallen kann.
Mit diesen Überlegungen und mit Hilfe von Prinzip (3) ist Tabelle I entstanden. Darin ist der gesamte URI-Namensraum spezifiziert, der für den Service benötigt wird. Die geschweiften Klammern kennzeichnen dabei Platzhalter, unter anderem für den Benutzernamen oder eine Bookmark-Id. all ist ein spezieller Benutzer, der alle am System registrierten Benutzer repräsentiert um von allen Bookmarks der Benutzer die 20 Neusten auswählen zu können.
2) Welche Repräsentationen sind sinnvoll?
Um die Möglichkeiten des uniformen Namensraums voll auszuschöpfen, bietet es sich an, die Ressourcen eines Services geschickt so zu verbinden, dass es möglich wird, ohne Zusatzinformationen den Dienst schrittweise in Anspruch nehmen zu können. Dies wird realisiert, in dem in den Repräsentationen der Ressourcen Links auf andere Ressourcen mit einem semantischem Zusammenhang eingebettet werden, wie es Prinzip (6) vorsieht. Dadurch wird explizit der Zusammenhang zwischen den Ressourcen ausgedrückt und auch eine automatisierte auf partiellem Wissen über den Services gestützte Nutzung begünstigt.
Für die vier hier gewählten Ressourcenarten gilt es nun, unter Beachtung von Prinzip (6), geeignete Repräsentationen zu wählen. In [13] wird ein Format für Bookmarks beschrieben, welches die nötigen Eigenschaften für den angedachten Service mitbringt und somit als Grundlage dienen wird. Das Format wird hier selbst nicht noch einmal von Grund auf erläutert, sondern es wird nur auf die für den Service nötigen Erweiterungen eingegangen. Genauere Informationen sind in der Spezifikation unter [13] zu finden oder in den Beispielen von [10], auf den dieser Beispiel-Service basiert.
<xbel version="1.0">
<bookmark href="http://.../content.html">
<title>Artikel zum Thema ...</title>
<desc>Diskutiert Zusammenhang von ...</desc>
<info>
<metadata owner="http://.../xbel-ext/baseuri">
http://example.com/testuser/bookmark/23
</metadata>
<metadata owner="http://.../xbel-ext/tags">
<tag>xml</tag><tag>REST</tag>
</metadata>
</info>
</bookmark>
</xbel>Abb. 3. Acht Prinzipien für RESTful Web Services nach [12]
Das Beispiel in Abb. 4 führt über die <metadata> Tags dem Standard eigene Erweiterungen zu, welche über das owner Attribut unterschieden werden können. Es wird über dieses Attribut die Art der im Tag hinterlegten Informationen angegeben. Die Metadaten mit der Identifikation xbel-ext/baseuri sind eingefügt worden, um dem Prinzip (6) Rechnung zu tragen, denn hier wird der URI des Bookmarks auf dem Server angegeben, über welche später z.B. Update- oder Löschoperationen möglich sind. Da die Bookmarks in diesem Format auch in der Repräsentation von Bookmarksammlungen Verwendung finden, ist es somit auch aus einer Sammlung heraus möglich einzelne Bookmarks später zu adressieren. Die zweite Erweiterung xbel-ext/tags wird verwendet um die dem Bookmark zugeordneten Schlüsselwörter anzugeben.
Die Repräsentation einer Bookmarksammlung wird im selben XBEL-Format angegeben, nur mit mehreren <bookmark>-Elementen unter dem <xbel>-Wurzelelement.
Für die Darstellung einer Liste von Schlüsselworten wird wie im Beispiel, eine einfache Sequenz von <tag>-Tags verwendet, welche zusätzlich in einem <tags>-Wurzelelement eingebettet ist.
Auf die Festlegung eines speziellen Formats für das Nutzerprofil soll hier gänzlich verzichtet werden. Für eine eventuelle Implementierung sei jedoch an Links auf die Schlüsselwortlisten des Nutzers und natürlich die Bookmarksammlungen erinnert.
3) Welche Methoden werden von den einzelnen
Ressourcen unterstützt?
Um diese Frage zu beantworten, macht sich eine tabellarische Auflistung gut. Als Erstes muss überlegt werden, welche Methoden auf die einzelnen Ressourcenarten anwendbar sein sollen, um sie anschließend geordnet nach den möglichen Methoden in die Tabelle eintragen zu können.
Dieses Vorgehen lässt sich aus dem Prinzip (4) ableiten und erhöht die Übersichtlichkeit beim Entwurf. Vollständig ausgefüllt beinhaltet die Tabelle somit eine komplette Beschreibung des Service-Interfaces und ist damit nicht nur ein Schritt zu einer vollständigen Dokumentation sondern auch Voraussetzung für die Implementierung und spätere Nutzung des Web Services durch andere Clients.
Durch Zuordnung von URIs zu anwendbaren Methoden wird die Anwendung von Prinzip (5) erleichtert. An diesem Punkt wird die konzeptionelle Integrität des URI-Namensraums geprüft. Sind alle GET-Anfragen seiteneffektfrei und führen sich nicht zu Modifikationen an den Ressourcen? Zum Beantworten dieser Frage sollten auch die Eigenschaften safe und idempotent überprüft werden. Zur Identifikation von Seiteneffekten sei noch angemerkt, dass Mechanismen wie Logging auf dem Webserver in diesem Fall nicht als echter Seiteneffekt gezählt werden, da diese nicht die Datenbasis des Services selbst betreffen. Der Vollständigkeit halber sollten in diesem Schritt auch die anderen Methoden noch auf ihre semantische Korrektheit im Sinne von [9] geprüft werden.
Methodenzuordnung
| Art der Ressource oder Methode | Repräsentation | Beschreibung |
|---|---|---|
| Bookmark | ||
| GET | XBEL-Dokument mit einzelnem Bookmark | Abfragen eines Bookmarks unter {user}/bookmark/{id} |
| PUT | XBEL-Dokument mit einzelnem Bookmark | Aktualisieren eines Bookmarks unter {user}/bookmark/{id} |
| DELETE | keine notwendig | Löscht Bookmark unter {user}/bookmark/{id} |
| Bookmarksammlung | ||
| GET | XBEL-Dokument mit mehreren Bookmarks | Abfragen einer Bookmarksammlung unter {user}/bookmarks/ {user}/bookmarks/tags/{tag}/ {user}/bookmarks/date/{year}/ |
| POST | XBEL-Dokument mit einzelnem Bookmark | Hinzufügen eines Bookmarks zur eigenen Sammlung nur unter {user}/bookmarks/ |
| Nutzerprofil | ||
| GET | Nicht spezifiziert, z.B. HTML-Dokument | Einsehen des Nutzerprofils z.B. über eine HTML-Seite {user}/profile |
| POST | Formulardaten multipart/form-data kodiert | Ändern von Profildaten über ein HTML-Formular {user}/profile |
| Schlüsselwortliste | ||
| GET | Einfaches Tags-Listen Dokument | Abfragen von verwendeten Schlüsselworten {user}/keywords/ all/keywords/ |
Nach dem Ausfüllen von Tabelle II zeigt sich nun, dass durch ein geschicktes Design des URI-Namensraums für den Beispielservice, die aufgestellten Anforderungen ohne weiteres erfüllt sind und somit eine semantisch einwandfreie und damit interoperable Schnittstelle geschaffen wurde.
4) Welche Status-Codes bzw. Fehler können zurückgegeben werden?
Im HTTP werden verschiedene Status-Codes für die wichtigsten Situationen definiert und von diesen sollte möglichst gebrauch gemacht werden, um dem Interoperabilitätsgedanken Rechnung zu tragen, da besonders Fehler oft durch unterschiedliche Definitionen die Interoperabilität beeinträchtigen, auch wenn die Schnittstelle an sich sauber implementiert wurde. Wenn der Server die Anfrage nicht interpretieren kann, ist z.B. der Status-Code 400 zurückzugeben oder falls Fehler bei der Abarbeitung auf dem Server auftreten der Status-Code 500.
Aber nicht nur Fehler sondern auch Erfolgsmeldungen sollten standardkonform verwendet werden. So sollte auf das Hinzufügen eines Bookmarks zu einer Sammlung z.B. mit dem Status-Code 201 reagiert werden und entweder der URI zurückgegeben werden, unter dem das neue Bookmark zu finden ist, oder die komplette Repräsentation des Bookmarks.
Eine detaillierte Auflistung und Beschreibung der standardisierten Status-Codes ist in [9] Abschnitt 10 zu finden.
5) Dokumentation
Ein häufig unterschätzter Aspekt ist die Dokumentation eines Services. Prinzip (7) und (8) gehen daher explizit auf diesen Umstand ein. Die Repräsentationen der Ressourcen sollten immer in einem geeigneten Format spezifiziert werden, um einem Konsumenten die vollständige Nutzung zu ermöglichen. Für XML-Daten bieten sich hier die gängigen Spezifikationssprachen an, aber auch bei Binärformaten sollte stets eine Spezifikation zur Verfügung gestellt werden, um die Nutzung zu vereinfachen.
Für die Beschreibung der Servicestruktur an sich, ist es ebenso sinnvoll eine im besten Fall auch maschinenlesbare Spezifikation zu erstellen. Dies kann z.B. über die WSDL geschehen, welche voraussichtlich in der kommenden Version 2.0 die Beschreibungsmöglichkeiten für RESTful Web Services weiter verbessert oder – dann aber nicht unbedingt maschinenlesbar – mittels eines für den Menschen aufbereiteten Dokuments, z.B. als simple HTML-Seite.
Wie auf einer gängigen Internetseite sollte es auch für diese Services üblich sein, eine Eintrittseite bzw. Ressource zu erstellen, welche die für den Service wesentlichen Ressourcen referenziert, so wird es möglich über einen einzigen URI den gesamten Service verfügbar zu machen.
4. Weitere Einsatzmöglichkeiten und Vorteile
4.1. Transaktionen in ressourcenorientierten Web Services
Für die Realisierung von komplexen Geschäftsabläufen ist es unerlässlich die ACID-Eigenschaften (Atomicity, Consistency, Isolation, Durability) garantieren zu können. Nun ist die Frage, ob RESTful Web Services konzeptionell so etwas wie einen Transaktionsmanager zulassen, wo eine der Hauptgrundsätze ja die Zustandslosigkeit – im Sinne der Vermeidung von anfrageübergreifenden Sessioninformationen – des Servers ist. Eine Möglichkeit der Modellierung wäre, die Ressourcen so zu gestallten, dass es nicht nötig wird Transaktionen über mehrere Anfragen hinweg zu unterstützen. Falls dies nicht möglich ist, wäre der folgende Ansatz eine mögliche Lösung.
Denkbar wäre eine Ressource im Sinne eines Transaktionsmanagers, welcher Anträge auf Transaktionen verwaltet. Mittels einer Anfrage, die dem Transaktionsmanager einen Antrag übermittelt, ließe sich eine Ressource erstellen, welche über einen URI referenziert werden kann, die eine zusammenhängende Transaktion repräsentiert. Operationen welche nun den ACID-Eigenschaften genügen sollen, können mit einer Referenz auf diese Transaktionsressource auf dem Server durchgeführt werden, bzw. ihre Repräsentationen auf dem Server abgelegt werden. Um die Transaktion abzuschließen, wird ein weiterer Antrag an die Transaktionsmanager-Ressource gestellt, über den das Commit der Transaktion angestoßen wird. Abschließend kann die Transaktion beendet und die Transaktionsressource freigegeben werden.
4.2. Asynchrone Web Services
Für einige Arten von Services ist es wünschenswert eine zeitliche Entkopplung, zwischen dem Stellen der Anfrage und dem Erhalten einer Antwort darauf, realisieren zu können. Da HTTP selbst dafür keine Mechanismen vorsieht, bleibt hier nur die Möglichkeit, den Serviceanbieter entweder in bestimmten zeitlichen Abständen oder nach Vereinbarung auf Abarbeitung der Anfrage anzusprechen. Dies hat auch aus architektureller Sicht einige Vorteile. Durch dieses Vorgehen benötigt der Server selbst keinerlei Informationen über den Anfragesteller und muss auch keine Information oder Mechanismen verwalten, um sicherzustellen, dass die Antwort auch beim Anfragenden ankommt. Damit bleibt die Komplexität des Servers auch für asynchrone Ausführung von Anfragen auf der gleichen Höhe und zusätzlich vermeidet man Abhängigkeiten zu Schnittstellen, die eventuell anfragerbezogen sein könnten.
4.3. Direkt Adressierung im URI-Namensraum
Wie bereits angerissen ermöglicht die Verwendung des URI-Namensraums eine direkte Adressierung aller Ressourcen. Wenn hier zusätzlich noch eine Beschränkung auf Identifikatoren unter dem HTTP eingeführt wird, ermöglicht dies einen uniformen Umgang mit diesen Ressourcen über ein einziges Protokoll und damit prinzipiell weitreichender Interoperabilität.
Dazu im Gegensatz steht die Verwendung von SOAP als Grundlage für ein Applikationsprotokoll. Über diesen Ansatz sind die Ressourcen des Services nicht mehr direkt über einen eindeutigen URI zugänglich, sondern es muss der Weg über eine SOAP-Ressource genommen werden, welche die eigentlichen Ressourcen versteckt. Durch diese Maßnahme werden diese Ressourcen in einen eigenen Namensraum verlagert und somit eine direkte Adressierung deutlich erschwert, wenn nicht teilweise unmöglich gemacht, womit die Interoperabilität dieser Dienste, im Vergleich zu Diensten die einen gemeinsamen, den allgemeinen URI-Namensraum nutzen, eingeschränkt wird und dass obwohl die meisten SOAP-Web Service sich selbst dieses Vorteils bedienen und direkt über einen URI ansprechbar sind.
Ein weiterer Punkt für diese Form der Adressierung von Ressourcen ist das Discovery Problem. Auf HTTP-REST aufbauende Web Services sind ohne weiteres über allgemeine oder spezialisierte Web-Suchmaschinen auffindbar und erfordern somit keine zusätzliche Technologie.
4.4. Standards und Sicherheitsaspekte
Bei der Verwendung von HTTP als eine REST Implementierung, ergeben sich einige weitere Vorteile, so gibt es für die großen Problemfelder der Nutzerauthentifikation und Sicherheit bereits Lösungen, die erprobt sind. Unter anderem verschiedene Verfahren zur Authentifikation z.B. über Zertifikate oder auch Verschlüsselung z.B. durch HTTP over TLS.
Des Weiteren ist es ohne weiteres möglich, auch nicht-XML Daten effizient zu übertragen, was bei SOAP, da es komplett XML-basiert ist, problematisch bzw. ineffizient ist, wenn man nicht z.B. SOAP with Attachments nutzen kann, weil dies nicht von allen Clients unterstützt wird.
Mit der Verwendung von HTTP in einem aus semantischer Sicht richtigen Sinne wird außerdem das Filtern und Loggen der Anfragen möglich, wie es für Webseiten seit Langem üblich ist. Tools für Monitoring-Aufgaben lassen sich ebenso weiter verwenden, ohne sie speziell anpassen zu müssen.
4.5. REST vs. SOAP
Die oben genannten Vorteile resultieren überwiegend aus der Tatsache, dass ein einziges universelles Protokoll mit einer eindeutig spezifizierten Schnittstelle genutzt wird.
Dahingegen ist SOAP deutlich im Nachteil, wenn es um Interoperabilität geht. Der Hauptgrund dafür ist, dass SOAP im Eigentlichen nur ein Framework für applikationsspezifische Protokolle ist. Mit SOAP als Grundlage werden somit verschiedene eigene Protokolle spezifiziert, die für jeden Anbieter unterschiedlich sind. Dies schließt sämtliche Vorteile aus, die darauf basieren, dass es ein oder zumindest wenige gut verstandene, eindeutige Protokolle gibt. Darunter fallen nicht nur die Möglichkeiten, die Filter haben, welche auf Grundlage von HTTP arbeiten, sondern vor allem auch die integrativen Vorteile, da nicht nur ein Protokoll mit verschiedenen Ressourcen, sondern viele Protokolle mit potenziell vielen Ressourcen unterstützt werden müssen.
Ein weiteres in SOAP noch nicht gelöstes Problem ist die Integration der sich stets erhöhende Zahl von Standards, welche die Kompatibilität der SOAP-Implementierungen untereinander behindert. Unteranderem gilt dies für den kommenden WS-Addressing Standard, welcher es ermöglicht Service-Endpunkte und Nachrichten zu adressieren. Genau dieses Problem resultiert aus der Verlagerung der Ressourcen in einen neuen Namensraum und wird von HTTP-REST deutlich geschickter gelöst.
4.6. Integrationsaufwand bei Verwendung uniformer Schnittstellen
Allgemein ist der Aufwand zur Integration von n verschiedenen Knoten in einem Netz der Ordnung O(n2). Auch in einem auf einer REST-Implementierung aufsetzenden Netz ist dies a priori nicht anders als in Netz bei denen jeder Knoten über eine eigene Schnittstelle angesprochen wird, da die Anzahl der vorstellbaren Ressourcen für ein spezielles Problem weiterhin nicht eingeschränkt ist. Dies könnte nur durch Standardisierung in diesem Problemfeld erreicht werden.
Allerdings gibt es Hypothesen, die besagen, dass der Gesamtaufwand deutlich geringer ist als bei Systemen, die jeweils unterschiedliche Schnittstellen nutzen, was offensichtlich nachvollziehbar ist, und sich dieser Gesamtaufwand deutlich in Richtung Ordnung O(n) bewegt und somit wesentlich effizienter ist als gängige Integrationsstrategien auf SOAP Basis.
5. Fazit
Der REST-Architekturstil beachtet viele grundsätzliche Punkte um die Interoperabilität von Systemen sicher zustellen schon im grundsätzlichen Design. So ist die Spezifikation einer uniformen und minimalen Schnittstelle, einer der wesentlichen Schritte zum Erreichen dieses Ziels. Auf HTTP-REST aufbauende sogenannten RESTful Web Services sind somit relativ einfach zu integrieren, da sie alle über dasselbe Protokoll kommunizieren und nicht wie bei SOAP über jeweils eigene anwendungsspezifische Protokolle. Darüber hinaus entfällt beim Erstellen solcher Web Services der Aufwand für die Spezifikation eines geeigneten und performanten Protokolls, da nicht nachrichten- sondern ressourcenorientiert entwickelt wird und das Protokoll durch HTTP bereits vorgegeben ist.
Ein weiterer wichtiger Faktor ist, dass RESTful Web Services in vollem Umfang von den für HTTP vorhandenen Technologien gebrauch machen können und es so für die meisten Probleme bereits Lösungen gibt. Seien dies nun Logging, Monitoring, Authentifizierung oder das Filtern von unerwünschten Operationen an einer Firewall.
Das Problem, des Integrationsaufwands, löst dieser Ansatz jedoch auch nicht vollständig. Dieser ist weiterhin der Ordnung O(n2), wenn auch tendenziell geringer als bei der Verwendung von nicht uniformen Schnittstellen.
Literatur
- [1] Roy Thomas Fielding, ”Architectural Styles and the Design of Network-based Software Architectures“ Ph.D. Dissertation, University of California, Irvine, 2000, S. 76ff.
- [2] M. Fowler, D. Rice, M. Foemmel, E. Hieatt, R. Mee, R. Stafford, Patterns of Enterprise Application Architecture. Addison Wesley, 2002.
- [3] M. Gudgin, M. Hadley, N. Mendelsohn, J.-J. Moreau, H. F. Nielsen, SOAP Version 1.2, 2003, http://www.w3.org/TR/soap12/
- [4] E. Christensen, F. Curbera, G. Meredith, S. Weerawarana, Web Services Description Language (WSDL) 1.1, 2001, http://www.w3.org/TR/wsdl
- [5] Carlos E. Perez (2005, März). Why REST is Better - Part 2 - Contract Based Protocols, http://www.manageability.org/blog/stuff/why-rest-part-2/view
- [6] Carlos E. Perez (2004, Juni). The RESTfulness of Speech Acts, http://www.manageability.org/blog/stuff/the-restfulness-of-speech-acts/view
- [7] Carlos E. Perez (2005, März). Artikelreihe Why REST is Better, http://www.manageability.org/blog/stuff/rest-explained-in-code/view
- [8] Eckhardt Holz, Script zur Vorlesung Softwarearchitektur, WS2005/06, Hasso-Plattner-Institut, Universität Potsdam
- [9] R. Fielding, J. Gettys, J. C. Mogul, H. Frystyk, L. Masinter, P. Leach, T. Berners-Lee. RFC 2616: Hypertext Transfer Protocol - HTTP/1.1. Internet Engineering Task Force, Juni 1999.
- [10] Joe Gregorio (2005, März). Show Me the Code http://www.xml.com/pub/a/2005/03/02/restful.html
- [11] Paul Prescod (2002, September). Common REST Mistakes http://www.prescod.net/rest/mistakes/
- [12] Roger L. Costello (2003, Januar). Building Web Services the REST Way http://www.xfront.com/REST-Web-Services.html
- [13] Fred L. Drake, Jr. The XML Bookmark Exchange Language, CNRI, Reston, USA, Oktober 1998. http://pyxml.sourceforge.net/topics/xbel/
- [14] Zitatsammlung verschiedener Autoren (2004, Mai). InterfaceGenericity http://rest.blueoxen.net/cgi-bin/wiki.pl?InterfaceGenericity
- [15] T. Berners-Lee, R. Fielding, L. Masinter. RFC 2396: Uniform Resource Identifiers (URI): Generic Syntax. Internet Engineering Task Force, August 1998.