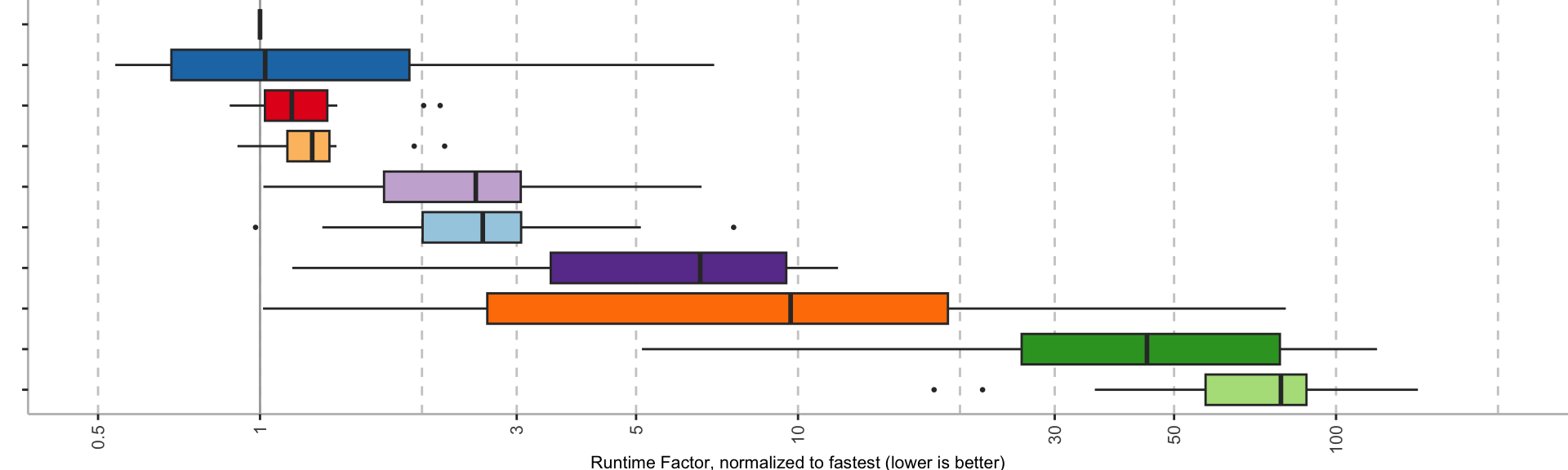
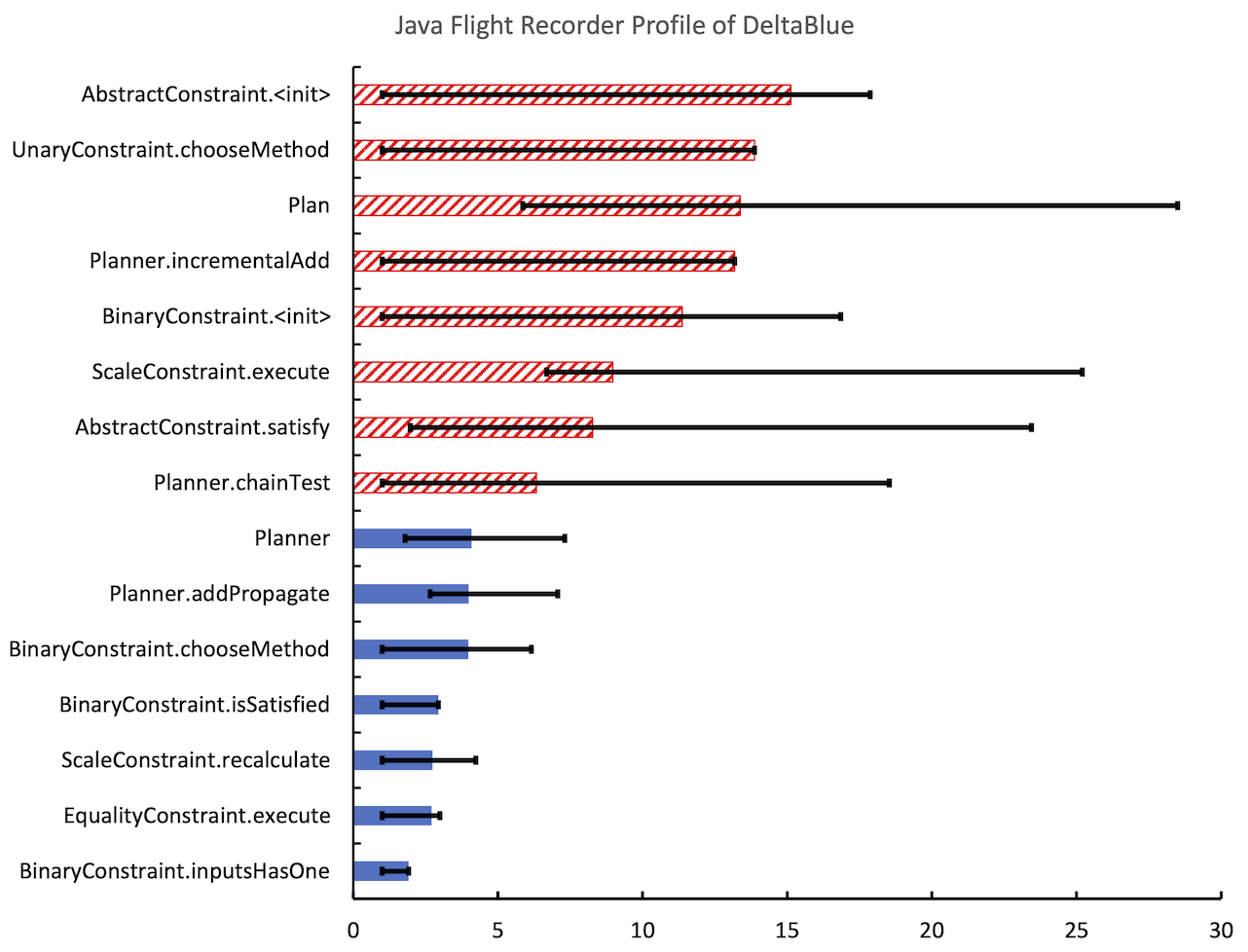
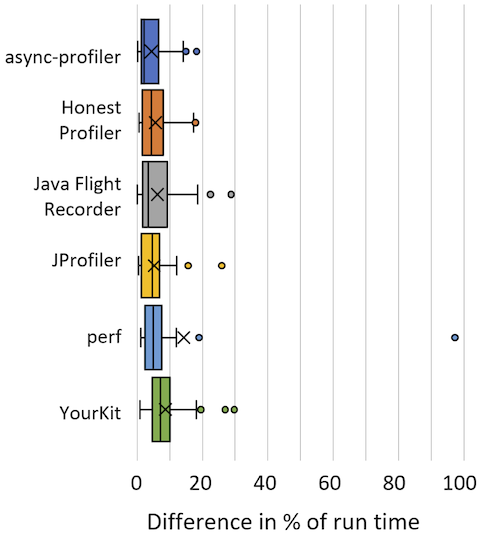
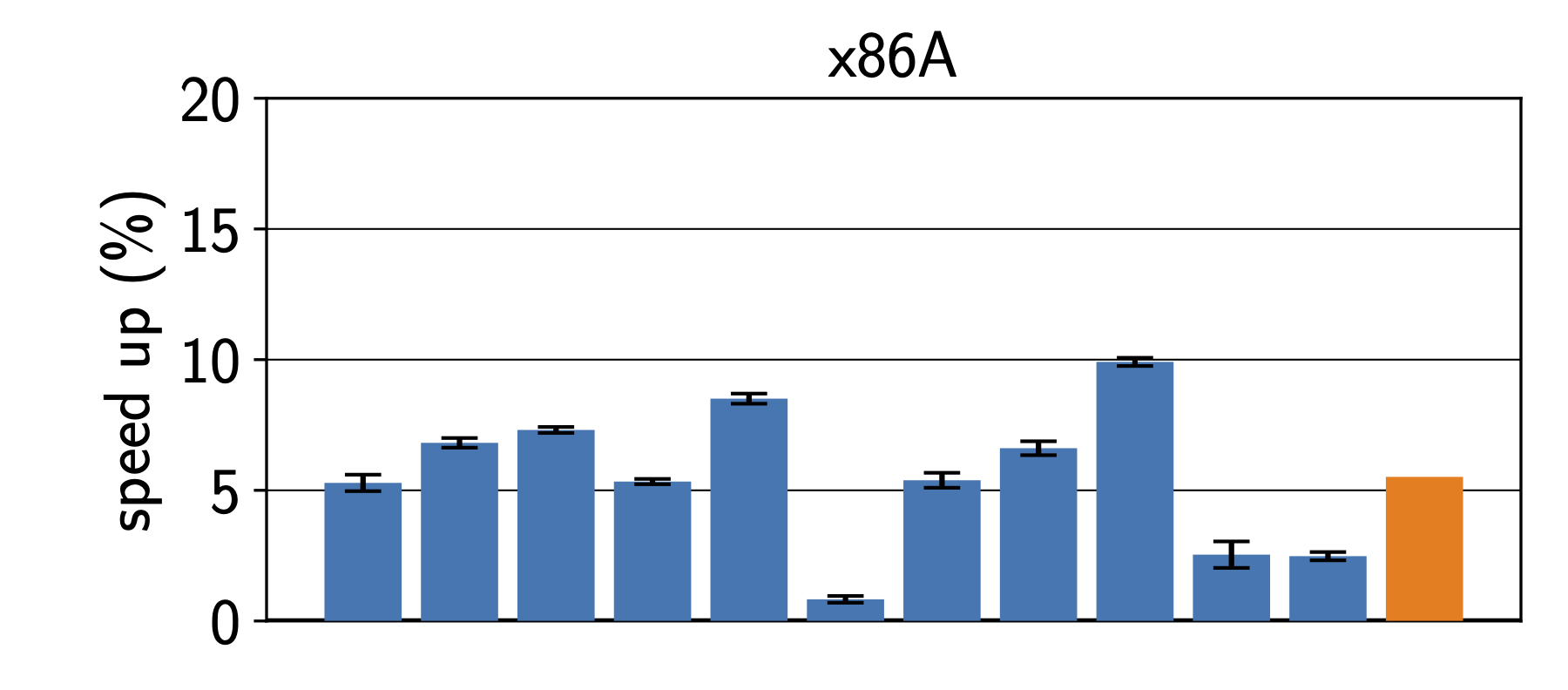
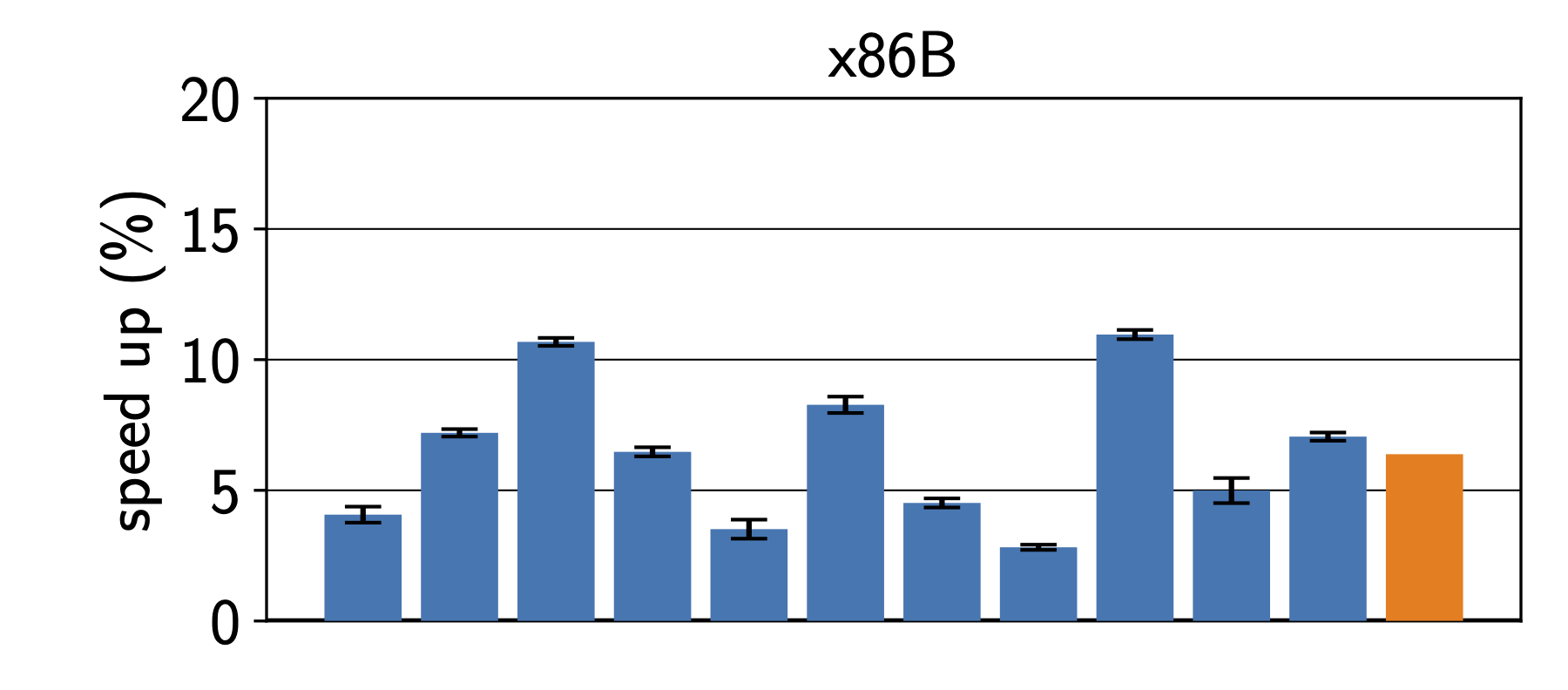
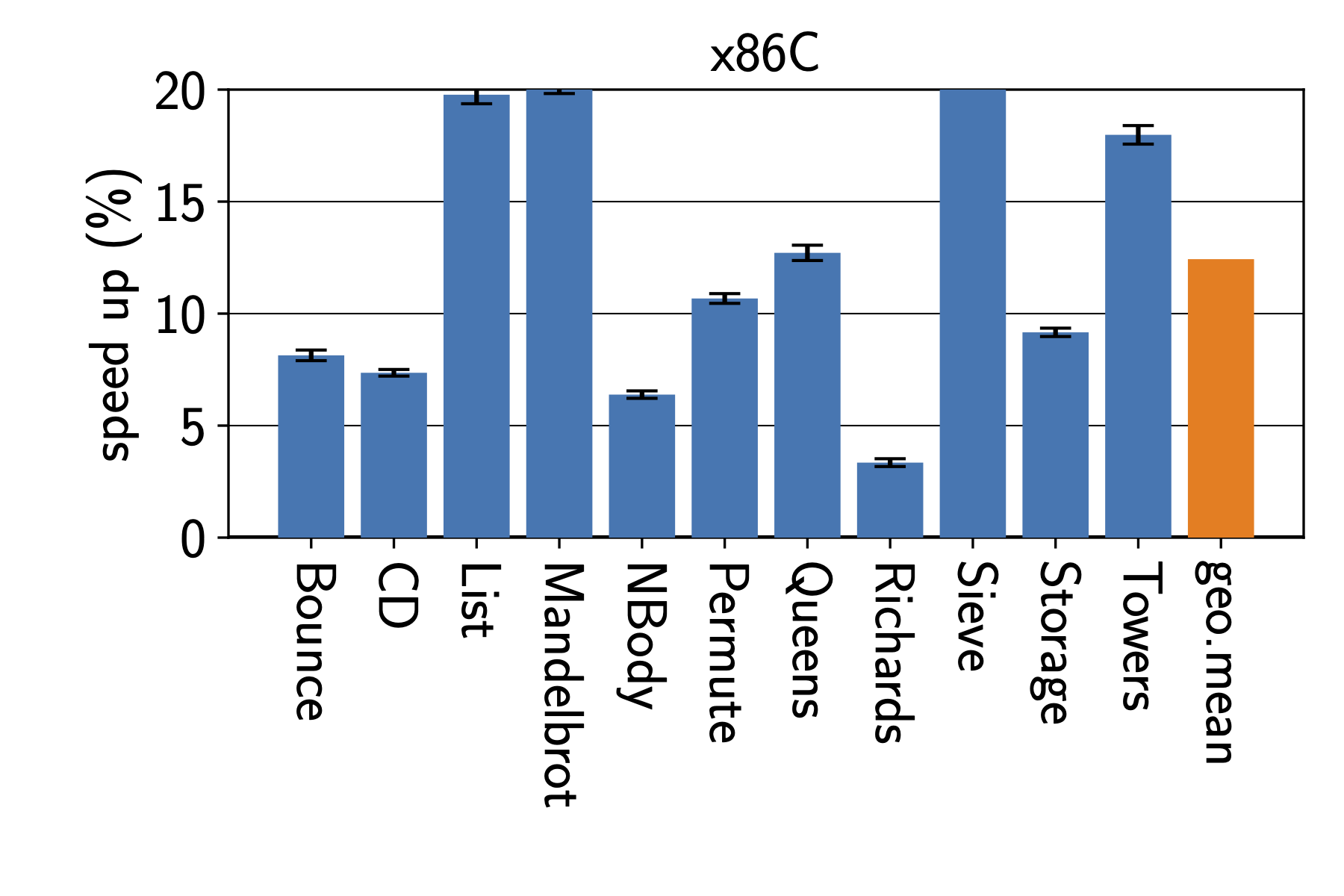
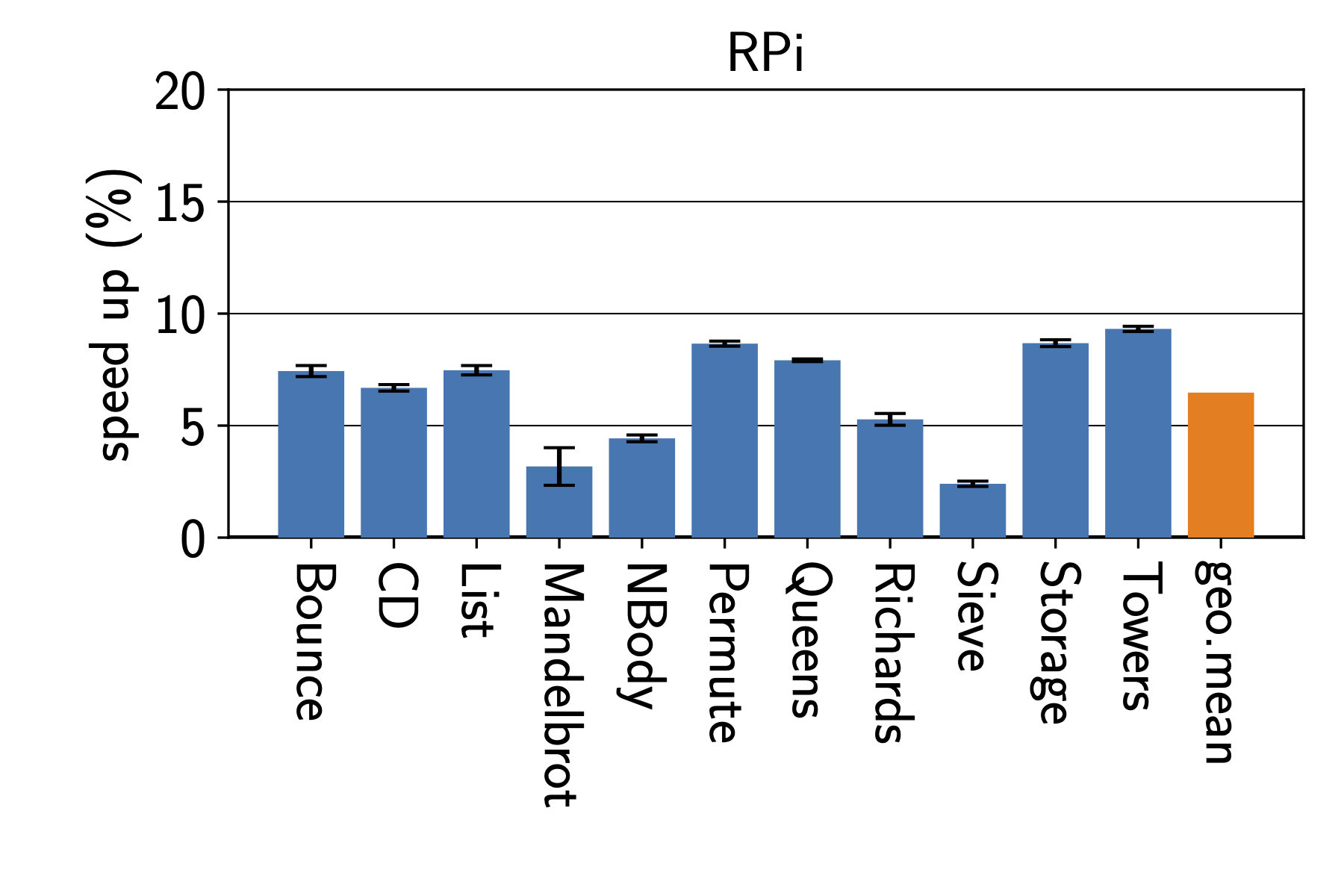
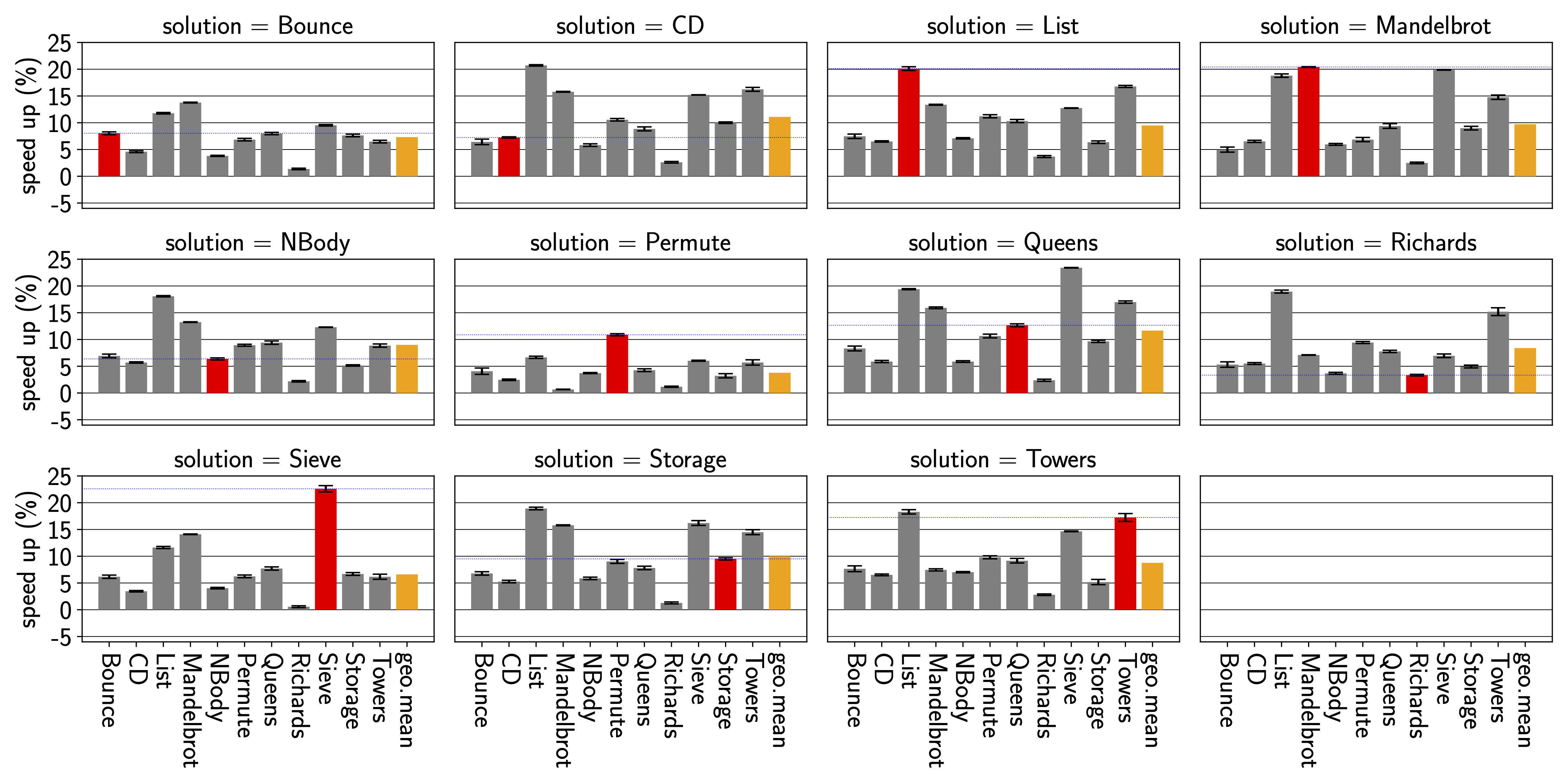
This post is motivated by discussions I have been having for, ehm, forever?
To encourage others to use good research practices and avoid bar charts, I’ll argue that people should use box plots as their go-to choice when presenting performance results. Of course, box plots aren’t a one-size-fits-all solution. However, I believe they should be the preferred choice for many standard situations. For some situations, more appropriate chart types should be chosen based on careful consideration.
Thus, box plots should be the default choice instead of the omnipresent bar chart. Or short: Box Plots, or Better!
When working on performance, I usually work with just-in-time compiling language runtimes, on which I would run various experiments that I want to compare. For examples, check the papers of Humphrey, Octave, and Sophie (copies are here). However, I believe the argument applies more generally beyond our own work.
Reason 1: Performance Measurements Are Samples from a Distribution
When we measure the performance of a system, we usually get a data point that has been influenced by many different factors. This is independent of whether we measure wall-clock time, the number of executed instructions, or perhaps memory. While we can control some factors and influence others, today’s systems are often too complex for us to fully understand them. For example, cache effects, thermal properties, as well as hard- and software interactions outside our control can change performance non-deterministically. In practice, we therefore often treat the system as a black box.11 I’d encourage people to dig deeper, but I’m aware that time does not always allow for it. Treating it as a black box then of course requires us to repeat our experiments multiple times to be able to characterize the range of results that are to be expected. Statisticians would perhaps describe our measuring as “sampling a distribution”.
And this is the point where box plots come in. They are designed to be a convenient way to characterize distributions. Let’s assume we have an experiment A and B, and we have taken 50 measurements each. Figure 1 shows the results of our experiments as box plots.

including annotations for the key elements of a box plot.
I annotated the box plot for A with some key elements, including the median, 25th, and 75th percentile. We also see the notion of an interquartile range, which tells us a bit about the shape of the result distribution and outliers, i.e., typically all measurements that are further from the 25th and 75th percentile than 1.5x the interquartile range.
Wikipedia has a good overview of box plots that also goes deeper.
Reason 2: Allows Detailed Visual Comparison
With box plots, we have enough details to see that the two experiments behave differently in a number of ways.
The median lines tell us that A is usually faster than B. However, we also see that A is not always faster than B, because the results are further spread out. In the worst case, A takes 19 seconds, which is more than B’s worst case of 15 seconds. While the main half of all data points for both experiments don’t overlap, we see that a good chunk of A’s results still fall within what’s often not considered to be outliers, i.e., the range between the 75th percentile with 1.5x of the interquartile range added.
By looking at the figure and comparing these plots, I believe we can get a reasonable intuition of the performance tradeoffs of the two options.
Reason 3: Box Plots Give Enough Details
The above analysis of the results would not have been possible for instance with a classic bar chart as shown in Figure 2.

Bar charts are often used to compare the performance of two or more systems or experiments. However, they show only three values per bar, typically a chosen “measure of centrality”, and some form of “error”. Very common are here things like the arithmetic mean, geometric mean, harmonic mean, and perhaps the median. Each of these has different properties, and one has to carefully think about which one to use based on the type of data one is working with (or perhaps not). At this point one also still has to chose how to characterize measurement errors.
This means that bar charts are less standardized than box plots, and one has to be explicit about what is shown.

To just give one example, Figure 3 is the same data but shows the median and the 25th and 75th percentile instead of the mean and standard deviation.
Since we show different sets of statistics, our impression of the results somewhat changes. Of course, this is the power of visualization and picking statistics. We can draw attention to specific aspects of the data. Figure 3 would lead me to conclude that A is always better than B, while Figure 2 would make me wonder what the underlying data looks like to understand how we got to the depicted standard deviation.
Compared to our box plot in Figure 1, the choice of statistics to show, and the reduced number of details we see here can result in misleading others and ourselves. Thus, I’d strongly argue that bar charts are neither a good default to represent data during data analysis, nor when presenting the final insights in a paper. They show too few details, oversimplifying an often more complex story.
Reason 4: Box Plots Don’t Overwhelm With Details
Of course, we could also go in the other direction and choose a plot type that shows much more detail.
Let’s start with Figure 4, which shows a violin plot. I selected here a version that shows just the density distribution of our results. One could go and highlight specific statistics on it for clarity of course. However, just looking at Figure 4, we get a more detailed look at how our measurements are distributed. From this, we see very clearly that B’s results are grouped much tighter together, and at each end, i.e., at 9 and 15 seconds, there are outliers. A on the other hand, is much more stretched out, though, a good chunk of the results are indeed roughly in the area indicated by the box plot previously. Though, what we see here also is that the area is wider and stretches from perhaps 8 to 15, only outside of which we likely have significantly fewer samples. We did not see these details on Figure 1.

For data analysis, this way of looking at the data is very helpful, because it allows us to see the underlying distribution. For reporting data in a paper, this might however be too detailed, in the sense that it is not as easily interpretable visually and makes drawing conclusions harder.

While not ideal for final reports, violin plots are useful during analysis. Perhaps one wants to go even a step further and use a combination of violin and box plot together with the raw data and the mean during analysis. An example of this is shown in Figure 5. While the plot is very busy and not suitable for a paper, I’d think, it prevents us from jumping to conclusions based on data summaries.
If you’re analyzing your data in R, a package like ggstatsplot might be a good solution.
Reason 5: They Are Very Versatile
Box plots can be used for many different purposes, independent of the type of distribution of data one wants to visualize, for different types of experiments, and to represent experimental data, as well as data summaries.
Because box plots visualize selected “percentile statistics”, we can use them without having to adapt them for specific experiments or types of distributions. They are nonparametric, i.e., one does not have to select any parameters for specific input data. This is useful for performance evaluations, because we do not generally know what type of distribution we are dealing with, and samples are not generally independent, which makes the use of various other statistical tools more complicated.

Figure 6 shows box plots for three different distributions. Important here is that neither of these experiments gives normally distributed data. Nonetheless, we can use box plots to describe them more abstractly and see certain key details such as A being skewed to the left, B slightly less so but much more narrow, and C having outliers to the left, with a small skew to the right.
So far, I have used examples where there was an experiment A and B, and perhaps C. Though, often we may want to understand the relation of perhaps two variables. This might be in the sense of scaling a computation over multiple processor cores. Figure 7 shows a box plot that visualizes data for such a hypothetical experiment.

While one would often use line charts for such scaling experiments, box plots can be used here as well. One can still see the rough shape of a line, but we do not lose sight of the distribution of our experimental data. Arguably, Figure 7 is very busy though, and a line chart with a confidence interval or similar would look better (Python, ggplot).
We can also see that box plots “scale” reasonably well themselves in the sense that they work for data that is spread out as well as for data that is very closely grouped. For example for B, we see the values at x-axis point 1 to be very narrowly together. Similarly for A, we see at 20 that data is tightly grouped. In either case, we still have the complete power of the box plot and can draw conclusions.
If we would now want to summarize these results, we can of course use box plots!

Figure 8 shows a summary. The plot at the top uses the medians for each of the experiments over the variable that went from 1 to 20. So, for A and B, we have 20 values each, and plot them as box plots. Note, for this to be a valid statistic, technically the medians have to be derived from independent samples, so, you may need to consult your friendly neighborhood statistician.
In the bottom plot, I used the raw data of all experiments. In a way this still “works”, and results in a very similar box plots in this case. Though, here the meaning changes and of course whether you can do this with your data is something you need to ask your statistician about. I think, common wisdom in our field is to first normalize the data and then “bootstrap” it. This would give us bootstrapped medians etc. The median is then technically from a normal distribution of independent samples, and standard statistics are legal again.
Conclusion: Box Plots Answer Important Questions At A Glance. Use Box Plots, Or Better!
When it comes to writing academic papers, I do believe that box plots are a much better default choice for communicating performance results than bar charts are.
The key reasons for me are:
- they are a concise representation of the result distribution
- they allow a visual comparison of more than the most basic statistics
- and thus, answer more questions than bar charts
- but without making things too complicated
- they are also more standardize, and thus, remain more readable when taken out of context
- and they can be used sensibly for a wide range of use cases
So, for me box plots strike a good overall balance, which makes them a good standard choice for papers.
Though, as mentioned earlier, they are not a universally best choice either. For data analysis, one would want more details, and for specific use cases or types of data distributions, e.g., bi- or multi-modal distribution, other types of plots are more suitable. I can recommend this piece with many examples where other types of plots than box plots may be better choices.
For questions, comments, or suggestions, please find me on Twitter @smarr or Mastodon.
]]>